Управляющие сигналы — это… Что такое Управляющие сигналы?
- Управляющие сигналы
16. Управляющие сигналы
Сигналы для пуска и контроля выполнения функций ФЕ(П) ИИС. Управляющие сигналы подразделяются на командные и контрольные
Словарь-справочник терминов нормативно-технической документации. academic.ru. 2015.
- Управляющие модули,
- Управляющие системы
Смотреть что такое «Управляющие сигналы» в других словарях:
управляющие сигналы — Сигналы, передаваемые между различными частями коммуникационной системы как часть механизма управления системой (например, сигналы RTS, DTR или DCD). [http://www.lexikon.ru/dict/net/index.html] Тематики сети вычислительные EN control signals … Справочник технического переводчика
СТ СЭВ 1610-79: Приборы электронные измерительные. Интерфейс НИС-1. Логические и электрические условия, информационные, управляющие и программные сигналы
Командные сигналы (В-сигналы) — 17. Командные сигналы (В сигналы) Управляющие сигналы, подаваемые на ФЕ(П) и вызывающие выполнение определенной функции в ФЕ(П) Источник … Словарь-справочник терминов нормативно-технической документации
Контрольные сигналы (М-сигналы) — 18. Контрольные сигналы (М сигналы) Управляющие сигналы, выдаваемые ФЕ(П) и определяющие ее состояние Источник … Словарь-справочник терминов нормативно-технической документации
ГОСТ 21835-84: Устройства коммутационной техники связи управляющие.
 Термины и определения — Терминология ГОСТ 21835 84: Устройства коммутационной техники связи управляющие. Термины и определения оригинал документа: 31. Асинхронный режим работы программного управляющего устройства коммутационной техники связи Режим работы программного… … Словарь-справочник терминов нормативно-технической документации
Термины и определения — Терминология ГОСТ 21835 84: Устройства коммутационной техники связи управляющие. Термины и определения оригинал документа: 31. Асинхронный режим работы программного управляющего устройства коммутационной техники связи Режим работы программного… … Словарь-справочник терминов нормативно-технической документацииИнформационные сигналы (1-сигналы) — 15. Информационные сигналы (1 сигналы) Электрические сигналы, несущие информацию о величине или состоянии исследуемого объекта или процесса Источник … Словарь-справочник терминов нормативно-технической документации
Программные сигналы (Р-сигналы) — 19. Программные сигналы (Р сигналы) Сигналы, определяющие режим работы ФЕ(П), а также алгоритм обработки информационных сигналов без непосредственного влияния на пуск Источник … Словарь-справочник терминов нормативно-технической документации
система — 4.48 система (system): Комбинация взаимодействующих элементов, организованных для достижения одной или нескольких поставленных целей. Примечание 1 Система может рассматриваться как продукт или предоставляемые им услуги. Примечание 2 На практике… … Словарь-справочник терминов нормативно-технической документации
часть — 3.7 часть (part): Часть исследуемой системы. Примечание Часть может быть физической (например, аппаратные средства) или логической (например, шаг в последовательности операций). Источник: ГОСТ Р 51901.11 2005: Менеджмент риска. Исследование… … Словарь-справочник терминов нормативно-технической документации
КОМПЬЮТЕР — устройство, выполняющее математические и логические операции над символами и другими формами информации и выдающее результаты в форме, воспринимаемой человеком или машиной. Первые компьютеры использовались главным образом для расчетов, т.е.… … Энциклопедия Кольера
|
№ |
Наименование |
Заказчик |
год |
|
1 |
Информационно-управляющая система Мыльджинского газоконденсатного месторождения АСУТП УКПГ, АСУТП УДСК, АСУ ШФЛУ, АСУ котельной, АСУ водозаборных сооружений, система телемеханики, производственно-диспетчерская служба (I, II, III очереди)
Система управления: Fisher-Rosemount EMERSON RS3, EMERSON DeltaV. |
АО «ГАЗПРОМ» АО «Томскгазпром» |
1999 |
|
2 |
АСУ объектами энергоснабжения пос. Харасавей Система управления: Fisher-Rosemount ROC364, Intellution FIX32. |
АО «ГАЗПРОМ» АО «Надымгазпром» |
1999 |
|
3 |
Информационно-управляющая система Губкинского газового месторождения АСУТП УКПГ, САПКЗ, система телемеханики кустов газовых скважин и газопровода, производственно-диспетчерская служба. Система управления: АСУТП — EMERSON RS3 , САПКЗ – Quadlog, СТМ – ROC364, iFIX. Количество сигналов — 2670 |
ЗАО «ПУРГАЗ» |
2000 |
|
4 |
АСУТП Северо-Альметьевской установки комплексной подготовки нефти Система управления: EMERSON RS3. Количество сигналов — 350 |
АО «ТАТНЕФТЬ» |
2000 |
|
5 |
Информационно-управляющая система Восточно-Таркосалинского газоконденсатного месторождения АСУТП и САП УНТС, АСУТП и САП УДК, система телемеханики конденсатопровода, АСУ Э, Вторая очередь АСУТП и САПКЗ УНТС. Система управления: АСУТП — EMERSON DeltaV,  Количество сигналов — 4450 Количество сигналов — 4450
|
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2001 |
|
6 |
Информационно-управляющая система Северо-Уренгойского газоконденсатного месторождения (Западный купол) АСУТП УКПГ, САПКЗ, система телемеханики, производственно-диспетчерская служба. Система управления: АСУТП — EMERSON DeltaV, САП – ЭМИКОН, iFIX, СТМ – ROC364, iFIX. Количество сигналов — 1808 |
АО «НОРТГАЗ» |
2001 |
|
7 |
Информационно-управляющая система Восточно-Таркосалинского газового месторождения АСУТП УКПГ, САПКЗ, система телемеханики кустов газовых скважин, Вторая очередь СТМ, производственно-диспетчерская служба. Система управления: АСУТП — EMERSON DeltaV, САП – ЭМИКОН, iFIX, СТМ – SCADAPack, iFIX. Количество сигналов — 3000 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2001 |
|
8 |
АСУТП УППГ Вьюжного газового месторождения. Система управления: контроллеры Modicon, SCADA — iFIX. Количество сигналов — 300 |
ООО «ЯнгПур» |
2001 |
|
9 |
Система автоматического газового пожаротушения НПС «Невская», «Кириши», «Приморск». Система управления – ЭМИКОН. |
АО «ТРАНСНЕФТЬ» |
2001 |
|
10 |
Система автоматики нефтеперекачивающей станции «Суторминская»
|
АО «ТРАНСНЕФТЬ» АО «Сибнефтепровод» |
2001 |
|
11 |
Информационно-управляющая система Северо-Васюганского газоконденсатного месторождения АСУТП УКПГ, САП, АСУТП котельной
Система управления: EMERSON DeltaV. |
АО «ГАЗПРОМ» АО «Томскгазпром» |
2002 |
|
12 |
АСУТП Ольховской дожимной насосной станции. Система управления: ПЛК SMART PEP Modular Computers, SCADA – InTouch Wonderware. Количество сигналов – 200. |
АО «ТНК» АО «Оренбургнефть» |
2002 |
|
13 |
Информационно-управляющая система Западно-Таркосалинского газоконденсатного месторождения АСУТП УКПГК и САПКЗ (I и II очередь). Система управления: ЭМИКОН ЭК-2000, SCADA-iFIX |
ООО «Энерготехгрупп» |
2003 |
|
14 |
АСУТП и САПКЗ УКПГ Западно-Озерного газового месторождения. Система управления: АСУТП — EMERSON DeltaV, САПКЗ – ЭМИКОН, iFIX. Количество сигналов — 500 |
АО «Сибнефть-Ноябрьскнефтегаз» |
2003 |
|
15 |
АСУТП ЦПС Южно-Мыльджинской группы месторождений. Система управления: ПТК SIMATIC PCS7 Siemens, EMERSON DeltaV. Количество сигналов — 1325 |
АО «Томская нефть» |
2003 |
|
16 |
САПКЗ Западно-Таркосалинского газоконденсатного месторождения
Система управления: ЭМИКОН, Intellution iFIX. |
ООО «Энерготехгрупп» |
2003 |
|
17 |
САП резервуарного парка РВС-5000 |
АО «ТАТНЕФТЬ» |
2003 |
|
18 |
Информационно-управляющая система Ханчейского нефтегазоконденсатного месторождения АСУТП УКПГ и САП, АСУТП УНТС, система телемеханики кустов газовых скважин, газопровода, производственно-диспетчерская служба. Система управления: АСУТП — EMERSON DeltaV, САП – ЭМИКОН, iFIX, СТМ – SCADAPack, iFIX. Количество сигналов — 1950 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2004 |
|
19 |
Информационно-управляющая система Юрхаровского газоконденсатного месторождения АСУТП УКПГ, САПКЗ, система телемеханики кустов скважин, газопровода и конденсатопровода, подсистема управления водозаборными сооружениями, АСУ Э, производственно-диспетчерская служба. Система управления: АСУТП, САПКЗ — EMERSON DeltaV, СТМ – ROC364, iFIX. Количество сигналов — 3000 |
ООО «НОВАТЭК-Юрхаровнефтегаз» |
2004 |
|
20 |
САПКЗ УКПГ Вынгаяхинского газового месторождения Система управления: Siemens QuadLog. Количество сигналов — 1100 |
ОАО «ГАЗПРОМ» ООО «Ноябрьскгаздобыча» |
2004 |
|
21 |
САПКЗ УППГ Еты-Пуровского газового месторождения. Система управления: Siemens QuadLog. Количество сигналов — 250 |
ОАО «ГАЗПРОМ» ООО «Ноябрьскгаздобыча» |
2004 |
|
22 |
АСУТП и САП Восточно-Таркосалинского нефтяного месторождения. Система управления: контроллеры SCADAPack, SCADA — iFIX. Количество сигналов — 450 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2004 |
|
23 |
АСУТП ГРС поселка Тарко-Сале. Система управления: контроллеры SCADAPack, SCADA – Trace Mode. Количество сигналов — 100 |
2004 |
|
|
24 |
АСУТП ГРС на скважине 71. Система управления: контроллеры SCADAPack, SCADA – Trace Mode. Количество сигналов — 100 |
2004 |
|
|
25 |
АСУТП УКПГ-2 Оренбургского ГПУ |
АО «ГАЗПРОМ» ООО «Оренбурггазпром» |
2004 |
|
26 |
Система телемеханики газосборных сетей |
ООО «НОВАТЭК Юрхаровнефтегаз» |
2004 |
|
27 |
САПКЗ УКПГ Находкинского газового месторождения. |
ООО «Ямалнефтегаз» |
2004 |
|
28 |
Система автоматики резервуарного парка «Западный Сургут» |
АО «ТРАНСНЕФТЬ» АО «Сибнефтепровод» |
2005 |
|
29 |
САППСиКЗ ГТЭС Ватьеганского месторождения. Система управления: Siemens PCS7 (контроллеры SIMATIC серии S7-400). Количество сигналов — 250 |
ООО «ЛУКОЙЛ–Западная Сибирь» |
2006 |
|
30 |
АСУТП пункта сдачи-приёмки нефти «Завьялово». Система управления: Siemens PCS7 (контроллеры SIMATIC серии S7-400). Количество сигналов — 1000 |
ООО «Норд Империал» |
2006 |
|
31 |
АСУТП пункта сдачи-приёмки нефти «Лугинецкое». Система управления: Siemens PCS7 (контроллеры SIMATIC серии S7-400). Количество сигналов — 1000 |
ООО «Норд Империал» |
2006 |
|
32 |
АСУТП НТС-2 Ханчейского газоконденсатного месторождения
Система управления: EMERSON DeltaV. |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2007 |
|
33 |
Информационно-управляющая система Уренгойского месторождения, Участок № 1А Ачимовских залежей АСУТП и ПАЗ, САПКЗ, СТМ, АСУ Э. Система управления: АСУТП, ПАЗ — EMERSON DeltaV, САПКЗ – Quadlog. СТМ – ROC800. Количество сигналов — 6000 |
ООО «Ачимгаз» |
2008 |
|
34 |
Система телемеханики сбора и транспорта газа Юрхаровского месторождения Система управления: EMERSON DeltaV. Количество сигналов — 200 |
ООО «НОВАТЭК-Юрхаровнефтегаз» |
2008 |
|
35 |
Система телемеханики газосборных сетей Система управления: ROC364, SCADAPack. Количество сигналов — 300 |
2008 |
|
|
38 |
Расширение системы телемеханики кустов газовых скважин газопровода Система управления: SCADAPack, iFIX. Количество сигналов — 500 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2008 |
|
39 |
АСУТП трубопровода «Верхнечонское газоконденсатное месторождение –«Восточная Сибирь – Тихий океан». |
ОАО «ТНК-BP» ОАО «Верхнечонскнефтегаз» |
2008 |
|
40 |
Информационно-управляющая система Северного участка сеноманской газовой залежи Губкинского газового месторождения АСУТП, САПКЗ, СТМ. Система управления: АСУТП, ПАЗ — EMERSON DeltaV, САПКЗ – Quadlog. СТМ – ROC364. Количество сигналов — 800 |
ЗАО «ПУРГАЗ» |
2008 |
|
41 |
Расширение Информационно-управляющей системы Ханчейского месторождения. Система управления: АСУТП — EMERSON DeltaV, САП – ЭМИКОН, GE iFIX, СТМ – SCADAPack, iFIX. Количество сигналов – 700 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2008 |
|
43 |
САППС и КЗ ГТЭС и ДКС Тевлинско-Русскинского месторождения: ТПП «Когалымнефтегаз». ПТК на базе системы PCS7 Siemens в составе пяти стоек управления, двух автоматизированных рабочих мест оператора. Количество сигналов — 992 |
ООО «ЛУКОЙЛ – Западная Сибирь» |
2009 |
|
44 |
САППС и КЗ КПКУГ Северо-Губкинского месторождения: ТПП «Ямалнефтегаз». |
ООО «ЛУКОЙЛ – Западная Сибирь» |
2009 |
|
45 |
САП ЦППН на Когалымском месторождении Система управления: Siemens PCS7 (контроллеры SIMATIC серии S7-400). Количество сигналов – 1000 |
ЗАО «ЛУКОЙЛ — АИК» |
2009 |
|
46 |
АСУТП по проекту «Реконструкция пристани № 5 Западного района ОАО «Новороссийский морской торговый порт». Система выполнена на базе программно-технического комплекса SIMATIC S7300 Siemens. Количество сигналов – 216 |
ОАО «Новороссийский морской торговый порт» |
2009 |
|
47 |
АСУ и ПАЗ по проекту «Реконструкция комплекса перевалки нефтепродуктов». Система выполнена на базе PCS7 Siemens. Количество сигналов – 576 |
ОАО «ИПП» |
2009 |
|
48 |
АСУТП и САП УКПГ Стерхового месторождения. ПТК АСУТП на базе EMERSON DeltaV в составе: 4 стойки управления, 3 АРМа — 1800 сигналов с учетом резерва 20%. ПТК САП на базе контроллеров КСАП-01 ЭМИКОН в составе: 4 стойки управления, 1 АРМ — 832 сигнала с учетом резерва 20%. |
ООО «ПурНоваГаз» |
2009 |
|
50 |
АСУТП кустов газовых скважин «Обустройство Восточно-Уренгойского Лицензионного участка». Система управления: Allen-Bradley ControlLogix. Количество сигналов – 850 |
ОАО «ТНК-BP» ЗАО «Роспан Интернешнл» |
2009 |
|
51 |
АСУТП кустов газовых скважин «Обустройство Ново-Уренгойского Лицензионного участка». Система управления: Allen-Bradley ControlLogix. Количество сигналов – 1000 |
ОАО «ТНК-BP» ЗАО «Роспан Интернешнл» |
2009 |
|
52 |
АСУТП и САП УКПГ ДКС газоконденсатного промысла Восточно-Таркосалинского месторождения. Система управления: EMERSON DeltaV. Количество сигналов – 900 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2010 |
|
53 |
Система телемеханики Стерхового месторождения. Система управления: Control Microsystems, контроллеры SCADAPack, Clear SCADA. Количество сигналов – 1200 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2010 |
|
54 |
АСУТП объекта «Обустройство сеноманской газовой залежи. |
ОАО «Газпромнефть- Ноябрьскнефтегаз » |
2010 |
|
55 |
САППС и КЗ на КС в районе ГЭТС на Ватьеганском месторождении. Система выполнена на базе PCS7 Siemens, SIMATIC серии S7-400. Количество сигналов – 150 |
ООО «ЛУКОЙЛ-Информ» |
2010 |
|
56 |
АСУ котельной п.Пионерный Система управления: SCADAPack. Количество сигналов – 150 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2010 |
|
57 |
Узел редуцирования топливного газа Южного Узла отбора и учёта газа. Система управления на базе контроллеров STARDOM и ПО верхнего уровня FAST/TOOLS Yokogawa в составе: 1 стойки управления, 1 АРМа. Количество сигналов — 771 |
Sakhalin Energy Ltd |
2011 |
|
58 |
Система контроля и управления электрическими сетями Южного Узла отбора и учёта газа, на базе контроллеров STARDOM и ПО верхнего уровня FAST/TOOLS Yokogawa в составе: 1 стойки управления (3 секции), 1 АРМа. Количество сигналов — 1096 |
Sakhalin Energy Ltd |
2011 |
|
59 |
Система аварийного отключения, обнаружения пожара и загазованности Южного Узла отбора и учёта газа, Сахалин II, на базе контроллеров ProSafe RS и ПО верхнего уровня FAST/TOOLS Yokogawa в составе: 1 стойки управления, 1 АРМа. |
Sakhalin Energy Ltd |
2011 |
|
60 |
Система телемеханики кустов скважин Нефтяного промысла Восточно-Таркосалинского месторождения. Система управления: SCADAPack. Количество сигналов – 400 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2011 |
|
61 |
Узел редуцирования топливного газа Северного Узла отбора и учёта газа. Система управления на базе контроллеров STARDOM Yokogawa. Количество сигналов — 250 |
Sakhalin Energy Ltd |
2011 |
|
62 |
Система контроля и управления электрическими сетями Северного Узла отбора и учёта газа. Система управления на базе контроллеров STARDOM Yokogawa. Количество сигналов — 2100 |
Sakhalin Energy Ltd |
2011 |
|
63 |
Система аварийного отключения, обнаружения пожара и загазованности Северного Узла отбора и учёта газа. Система управления на базе контроллеров ProSafe Yokogawa. Количество сигналов — 300 |
Sakhalin Energy Ltd |
2011 |
|
64 |
Модернизация АСУТП УКПГ Южного участка Губкинского ГМ. |
ЗАО «Пургаз» |
2011 |
|
65 |
Реконструкция АСУТП (АСУ «Бункер»). АСУТП отгрузки нефтепродуктов на суда-бункеровщики в г.Новороссийске. Система управления Siemens PCS7. Количество сигналов — 400 |
ОАО «ИПП» |
2011 |
|
66 |
АСУТП централизованного узла учёта нефтепродуктов на ЛДПС «Черкассы». Система управления EMERSON DeltaV. Количество сигналов — 700 |
ОАО «УФАНЕФТЕХИМ» |
2012 |
|
67 |
АСУТП и САП ЦПС и ДКС (верхний уровень) Центрального участка Нефтяного промысла Восточно-Таркосалинского месторождения. Система управления: EMERSON DeltaV, ЭМИКОН, GE iFIX. Количество сигналов – АСУТП 2000, САП — 900 |
ООО «НОВАТЭК-ТАРКОСАЛЕНЕФТЕГАЗ» |
2012 |
|
68 |
Система телемеханики второй (резервной) нитки конденсатопровода участка 1А Ачимовских отложений Уренгойского месторождения. Система управления: EMERSON ROC800, DeltaV. Количество сигналов — 1000 |
ЗАО «АЧИМГАЗ» |
2012 |
|
69 |
Система телемеханики и система связи по объекту «Обустройство валанжинских залежей (БТ10, БТ11) Берегового газоконденсатного месторождения». |
ЗАО «Геотрансгаз» |
2012 |
|
70 |
Автоматическая система управления, регулирования и учёта газа. Узел подключения Берегового ГКМ к магистральному газопроводу «Заполярное-Уренгой I, II». Система управления: СТН-3000. Количество сигналов — 200 |
ЗАО «Геотрансгаз» |
2012 |
 Количество сигналов — 4350
Количество сигналов — 4350 Количество сигналов — 2850
Количество сигналов — 2850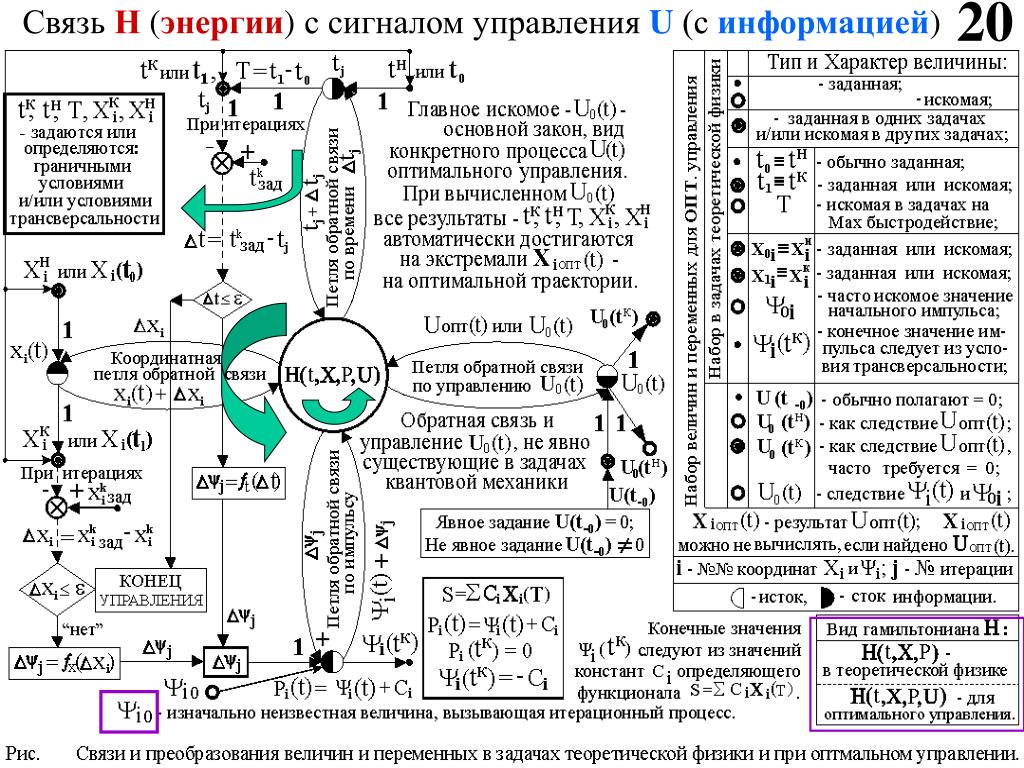

 Система управления: Siemens PCS7 (контроллеры SIMATIC серии S7-400). Количество сигналов — 1000
Система управления: Siemens PCS7 (контроллеры SIMATIC серии S7-400). Количество сигналов — 1000 Количество сигналов — 500
Количество сигналов — 500 Система управления: АСУТП – Yokogawa Centum, ПАЗ, САПКЗ – Yokogawa ProSafe, СТМ – Yokogawa STARDOM. Количество сигналов — 7000
Система управления: АСУТП – Yokogawa Centum, ПАЗ, САПКЗ – Yokogawa ProSafe, СТМ – Yokogawa STARDOM. Количество сигналов — 7000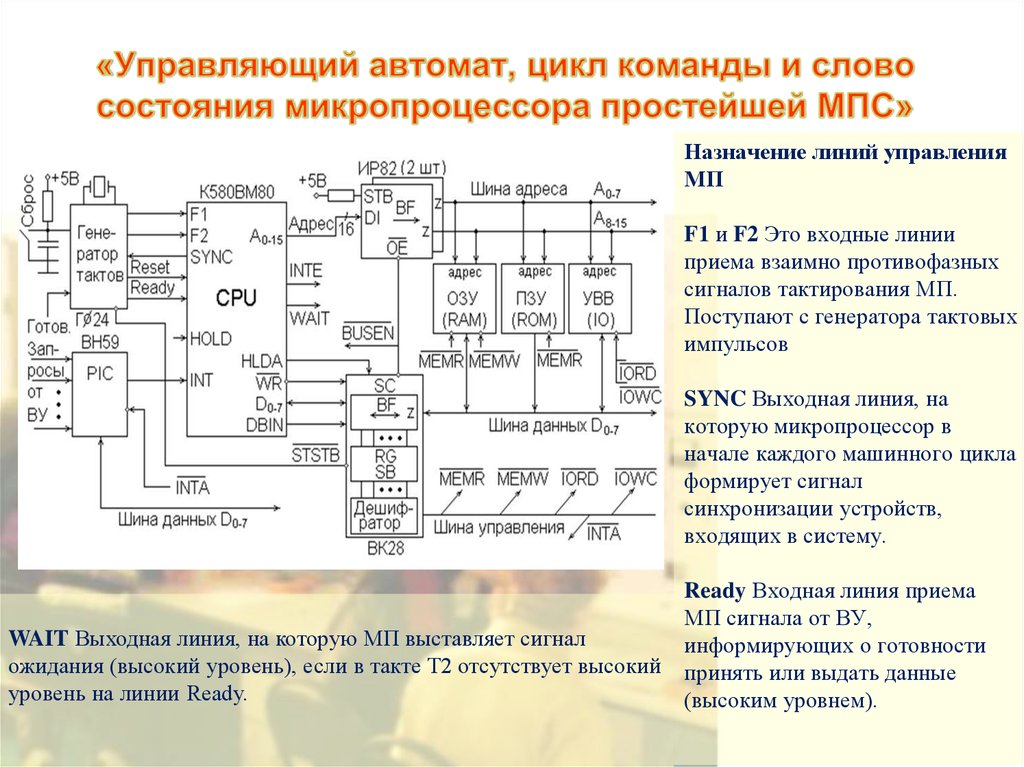 ПТК на базе системы PCS7 Siemens в составе трёх стоек управления и автоматизированного рабочего места оператора. Количество сигналов — 936
ПТК на базе системы PCS7 Siemens в составе трёх стоек управления и автоматизированного рабочего места оператора. Количество сигналов — 936 Количество сигналов — 2632
Количество сигналов — 2632 Новогоднее месторождение. Узел подключения газопровода». Система управления: SCADAPack, InTouch. Количество сигналов – 200
Новогоднее месторождение. Узел подключения газопровода». Система управления: SCADAPack, InTouch. Количество сигналов – 200 Система управления EMERSON DeltaV. Количество сигналов — 1700
Система управления EMERSON DeltaV. Количество сигналов — 1700 Система управления: Control Microsystems SCADAPack. Количество сигналов — 400
Система управления: Control Microsystems SCADAPack. Количество сигналов — 400Защита управляющих сигналов информационных систем Текст научной статьи по специальности «Компьютерные и информационные науки»
УДК 004.056.5
ЗАЩИТА УПРАВЛЯЮЩИХ СИГНАЛОВ ИНФОРМАЦИОННЫХ СИСТЕМ
И. С. Савельев, А. С. Тимохович Научный руководитель — В. В. Золотухин
Сибирский государственный аэрокосмический университет имени академика М. Ф. Решетнева Российская Федерация, 660037, г. Красноярск, просп. им. газ. «Красноярский рабочий», 31
E-mail: [email protected]
Рассматривается защита управляющих сигналов информационных систем.
Ключевые слова: защита, безопасность, защита информации, управляющие сигналы, сигналы, информационные системы, уровни защиты.
CONTROL SIGNAL PROTECTION IN INFORMATION SYSTEMS
I. S. Savelyev, A. S. Timohovich Scientific Supervisor — V. V. Zolotuhin
Reshetnev Siberian State Aerospace University 31, Krasnoyarsky Rabochy Av. , Krasnoyarsk, 660037, Russian Federation E-mail: [email protected]
, Krasnoyarsk, 660037, Russian Federation E-mail: [email protected]
In this paper we consider the protection control signals in information systems.
Keywords: protection, security, protection information, control signals, signals, information systems, levels of protection.
Одним из важнейших аспектов вопроса безопасности являются проблемы, возникающие при использовании каналов передачи данных. Злоумышленник может получить доступ к основной сети и выполнять роль второго доверенного лица для отправки всех команд на жизненно важные системы.
Прежде чем начать говорить о защите управляющих сигналов, необходимо рассказать о самом объекте защиты, то есть о сигнале. Сигнал — это физическая величина, которая изменяется во времени, пространстве или зависит от любой другой переменной, посредством которой информация может быть передана. Из этого следует, что термины «сигнал» и «информация» очень тесно связаны, а значит необходимо дать определение термину информация. Информация -это знания, переданные или полученные благодаря обучению, коммуникации, исследованиям, обучению в отношении конкретного факта или обстоятельства.
Но следует отличать простые информационные сигналы от сигналов управления. Управляющие сигналы — это сигналы, предназначенные для задания команд или выполнения конкретных действий над системами или устройствами, в которые они посылаются. Из этого следует, что управляющие сигналы отвечают за работоспособность всей системы.
Для того чтобы обеспечить защиту и безопасность таких сигналов, чаще всего они посылаются по отдельному каналу, который называется управляющим. А значит, если злоумышленник получит доступ к такому каналу, то он сможет контролировать действия, происходящие в системе, украсть важные и секретные сведения, изменить команды или полностью вывести из строя всю информационную систему. Поэтому обеспечение защиты управляющих сигналов является очень важной задачей.
Защита информации — это совокупность действий, направленных на предоставление и поддержание информационной безопасности.
Актуальные проблемы авиации и космонавтики — 2017. Том 2
Информационная безопасность — это набор стратегий для управления процессами, необходимыми для предотвращения, обнаружения и противодействия угрозам цифровой и нецифровой информации [2].
Со стороны информационной безопасности, информация должна обладать следующими требованиями:
— конфиденциальность — гарантирует, что содержание данных может быть доступно только тем пользователям, которые имеют на это права;
— целостность — гарантирует, что данные защищены от запрещенного изменения, удаления, создания и дублирования;
— аутентичность — гарантирует, что источником информации является именно то лицо, которое заявлено как ее автор;
— безопасность — гарантирует, что информация не изменяет направления и не перехватывается при передаче между оконечными точками;
— апеллируемость — гарантирует, что информацию можно привязать к ее автору и при необходимости доказать, авторство отправленного сообщения;
— доступность — гарантирует, что нет ограничений для зарегистрированных пользователей к доступу к информации, потокам данных и приложениям.
Таким образом, главной задачей подсистемы безопасности информационной системы является обеспечение указанных требований [1].
Чтобы гарантировать комплексное обеспечение защиты, параметры защиты должны применяться к системе сетевого оборудования и групп объектов, которые именуются уровнями защиты. Вместе, эти 3 уровня гарантируют полную безопасность системы.
Уровни защиты — это серия инструментов для гарантии безопасности сетей. Уровень инфраструктуры позволяет применять уровень услуг, а уровень услуг обеспечивает возможность применения уровня приложений. Архитектура защиты берет в учет то, что каждый из уровней имеет разные проблемы с безопасностью, и предоставляет гибкость противодействия возможным угрозам способом, наиболее подходящим для определенного уровня.
Уровни защиты определяют, где в продуктах должна быть обеспечена безопасность, путем обеспечения последовательной проверки сетевой безопасности. Например, первые проблемы безопасности рассматриваются для уровня инфраструктуры, затем для уровня служб и, наконец, уязвимости безопасности рассматриваются для уровня приложений.
Уровень защиты инфраструктуры состоит из различных составляющих сети, а также фрагментов сетевой передачи, защищенных характеристиками безопасности. Уровень инфраструктуры выступает в качестве основных строительных блоков сетей, их сервисов и приложений. Характеристиками элементов, принадлежащих к уровню инфраструктуры, можно назвать отдельные коммутаторы, серверы, в том числе линии связи между ними.
Уровень защиты служб защищает службы, предоставляемые продавцами услуг своим клиентам. Эти услуги варьируются от базового транспорта и присоединения к средствам поддержки услуг, таким как те, которые необходимы для обеспечения доступа в Интернет. Уровень безопасности служб используется для защиты изготовителей услуг и их клиентов, которые могут стать объектами угроз безопасности.
Уровень безопасности приложений сосредоточен на защите сетевых программ, к которым обращаются клиенты, используя услуги. Эти программы активируются сетевыми службами и состоят из базовой передачи файлов и приложения для просмотра веб-страниц. Сетевые приложения могут быть предоставлены сторонними поставщиками прикладных услуг [3].
Во избежание несанкционированного доступа к системе, должны применяться аутентификация и авторизация, гарантирующие безопасность, защиту, конфиденциальность и целостность информации и сигналов. Следует обеспечить защиту и конфиденциальность управляющих сигналов, прежде всего потому, что устройства имеют доступ к ним и управляют ими (например, информацию о перемещениях и время отправления сигналов).
Для исключения возможности исполнения злоумышленником роли дополнительного доверенного лица, защитить каналы передачи данных и расширить границы контролируемой зоны, при этом учитывая особенности используемых устройств, нужно создать надежный, защищен-
ный и доверенный канал между управляющим центром автоматизированной системы и конечными устройствами.
Из выше изложенного следует, что, зная измерения информации и три уровня защиты, можно надежно обеспечить защиту управляющих сигналов информационных систем.
Библиографические ссылки
1. Рекомендация МСЭ-Т X.805. Архитектура безопасности для систем, обеспечивающих связь между оконечными устройствами [Электронный ресурс]. URL: https://www.itu.int/rec/T-REC-X.805-200310-I/en (дата обращения: 15.04.2017).
2. Хорев П. Б. Методы и средства защиты информации в компьютерных системах. М. : Академия. 4-е изд. 2008. С. 6-31.
М. : Академия. 4-е изд. 2008. С. 6-31.
3. Конахович Г. Ф., Климчук В. П., Паук С. М., Потапов В. Г. Защита информации в телекоммуникационных системах. М. : МК-Пресс, 2005. 288 с.
© Савельев И. С., Тимохович А. С., 2017
Управляющие компании получили сигнал «Оттепель»
В связи с положительными температурами в период с 5 по 7 февраля единая дежурно-диспетчерская служба города оповестила руководящий состав управляющих организаций о принятии мер по обеспечению безопасности граждан.
По данным ФГБУ «Западно-Сибирское УГМС», с 5 по 7 февраля на территории города Новосибирска ожидается повышение температуры воздуха в дневные часы до +1°С, небольшой снег, порывы ветра до 17 м/с.
5 февраля: температура ночью −6..-8 °С, днем 0..-2 °С, ветер юго-западный 3-8 м/с. Ночью небольшой снег, днем без осадков, на дорогах — гололедица.
6 февраля: температура ночью −4..-6 °С, днем −1..+1 °С, ветер юго-западный, ночью 3-8 м/с, днем 7-12 м/с. Ночью без осадков, днем небольшой снег, на дорогах — гололедица.
7 февраля: температура ночью −5..-7 °С, днем −1..+1 °С, ветер юго-западный, днем 7-12 м/с, местами порывы до 17 м/с. Ночью и днем небольшой снег, на дорогах — гололедица.
Сегодня, 4 февраля, единая дежурно-диспетчерская служба мэрии передала по автоматизированной системе «Sprut» сигнал «Оттепель» управляющим компаниям в сфере жилищно-коммунального хозяйства.
Руководители управляющих организаций по эксплуатации жилого фонда должны обратить особое внимание на состояние крыш, срочно принять меры по очистке их от снега и сосулек. Кроме того, в местах возможного схода снега и наледи с кровель, козырьков, балконов и других конструкций сотрудники УК должны организовать работу по предупреждению и выставлению ограждений.
Жителям многоквартирных домов также необходимо устранить льдообразования со своих балконов и карнизов.
Специалисты департамента по чрезвычайным ситуациям, мобилизационной работе и взаимодействию с административными органами мэрии города Новосибирска напоминают: при возникновении чрезвычайных ситуаций необходимо обращаться по телефону 051.
Изменено 04.02.2020 16:45:49 Просмотров:управляющие сигналы нервной системы?пути распространения сигналов нервной системы ?влияние на
Нервная система – это система, которая регулирует деятельность всех органов и систем человека. Данная система обуславливает:
1) функциональное единство всех органов и систем человека;
2) связь всего организма с окружающей средой.
Нервная система имеет и свою структурную единицу, которая именуется нейроном. Нейроны – это клетки, которые имеют специальные отростки. Именно нейроны строят нейронные цепи.
Вся нервная система делится на:
1) центральную нервную систему;
2) периферическую нервную систему.
К центральной нервной системе относятся головной и спинной мозг, а к периферической нервной системе – отходящие от головного и спинного мозга черепно-мозговые и спинномозговые нервы и нервные узлы.
Также условно нервную систему можно подразделить на два больших раздела:
1) соматическая нервная система;
2) вегетативная нервная система.
Соматическая нервная система связана с человеческим телом. Эта система отвечает за то, что человек может самостоятельно передвигаться, она же обуславливает связь тела с окружающей средой, а также чувствительность. Чувствительность обеспечивается с помощью органов чувств человека, а также с помощью чувствительных нервных окончаний.
Передвижение человека обеспечивается тем, что с помощью нервной системы осуществляется управление скелетной мышечной массой. Ученые-биологи соматическую нервную систему по-другому называют анимальной, т. к. передвижение и чувствительность свойственны только животным.
к. передвижение и чувствительность свойственны только животным.
Нервные клетки можно разделить на две большие группы:
1) афферентные (или рецепторные) клетки;
2) эфферентные (или двигательные) клетки.
Рецепторные нервные клетки воспринимают свет (с помощью зрительных рецепторов), звук (с помощью звуковых рецепторов), запахи (с помощью обонятельных и вкусовых рецепторов).
Двигательные нервные клетки генерируют и передают импульсы к конкретным органам-исполнителям. Двигательная нервная клетка имеет тело с ядром, многочисленные отростки, которые называются дендритами. Также нервная клетка имеет нервное волокно, которое называется аксон. Длина этих аксонов колеблется от 1 до 1,5 мм. С их помощью осуществляется передача электрических импульсов к конкретным клеткам.
Управление технологическими процессами буровых установок (США)
Компания Varco International является ведущим поставщиком бурового оборудования и интегрированных систем управления процессами бурения нефтяных и газовых скважин. Новые системы управления на базе технологии Amphion, поставляемые компанией, основаны на применении сетей Ethernet. Эти системы обеспечивают эргономичное, эффективное и безопасное управление технологическими процессами современных буровых установок.
Описание системы
Системы управления, поставляемые Varco, являются системами высокой готовности, которые обеспечивают централизованный мониторинг, контроль и управление автоматизированными процессами бурения. Системы собраны на оборудовании компании Varco, ее партнеров и третьих производителей. Оператор системы осуществляет управление с эргономичного пульта бурильщика, который представляет собой комбинацию терминала с сенсорным экраном, кнопочного пульта и джойстиков. Комплекс средств наземного контроля обеспечивает формирование сигналов управления электрооборудованием и механизмами буровой установки. Основные технологические параметры, контролируемые системой, — частота вращения бурового долота (об/мин), осевая нагрузка на долото, крутящий момент, поток бурового раствора и др.
В качестве устройств связи в системе используются промышленные Ethernet-коммутаторы MOXA ED6008-MM-SC (эквивалентны EDS-408A-MM-SC), смонтированные в шкафы локального управления. Они обеспечивают мониторинг и управление процессами различного оборудования буровой. Каждый шкаф включает несколько устройств ED6008, которые передают управляющие сигналы локальным устройствам и отсылают данные с PLC, модулей Ethernet I/O и контрольных панелей на операторский пульт. Все локальные станции объединены друг с другом в оптоволоконное резервированное кольцо по разработанной компанией MOXA технологии Turbo Ring – такая резервированная сетевая инфраструктура позволяет оператору осуществлять все процессы в режиме реального времени. Резервирование сети и использование отказоустойчивых промышленных коммутаторов MOXA позволяют гарантировать высокую готовность системы управления буровой.
Схема сети объекта
Преимущества, определившие выбор оборудования
- Технология резервирования сети MOXA Turbo Ring позволяет объединять Ethernet-коммутаторы в резервированное кольцо со временем перехода на резервный канал менее 300 мсек.
- Защищенное исполнение устройств, отсутствие вентилятора и длительный срок наработки на отказ гарантируют длительную безотказную работу устройств в условиях буровой.
- Коммутаторы ED6008-MM-SC имеют порты многомодовой оптики, что позволяет защитить передаваемые данные от электромагнитных и радиопомех, а также увеличить дальность передачи данных.
- ED6008-MM-SC монтируется на DIN-рейку, что позволяет удобно разместить устройство в шкафу автоматики.
- Коммутатор ED6008 в режиме реального времени отсылает оператору оповещение по e-mail при возникновении различных сбоев, позволяя быстро устранять неполадки.
Оборудование MOXA
|
|
ED6008-MM-SC (эквивалентен EDS-408A-MM-SC )
|
«Газпром нефть» испытала на северных месторождениях грузовые беспилотники
Беспилотные автомобили, еще недавно казавшиеся фантастикой, постепенно становятся реальностью. Тестовые образцы сегодня можно встретить и на улицах Москвы, и на безлюдных просторах Западной Сибири и Заполярья. Все достоинства грузовых беспилотников сотрудники «Газпром нефти» смогли оценить этой весной: компания совместно с отечественными производителями грузовой техники — КАМАЗом и ГАЗом — провела два цикла испытаний умных машин на Ямале и в Югре
Тестовые образцы сегодня можно встретить и на улицах Москвы, и на безлюдных просторах Западной Сибири и Заполярья. Все достоинства грузовых беспилотников сотрудники «Газпром нефти» смогли оценить этой весной: компания совместно с отечественными производителями грузовой техники — КАМАЗом и ГАЗом — провела два цикла испытаний умных машин на Ямале и в Югре
Ермак — покоритель Сибири
Сложно найти более экстремальные условия для испытаний грузовых беспилотников, чем Гыданский полуостров Ямала ранней весной. В марте здесь еще стоят тридцатиградусные морозы, а метели набирают силу. Днем горизонта практически не видно. Белую пелену не могут разогнать даже штормовые ветра, летящие над тундрой с бешеной скоростью. Добавьте к этому сложный рельеф с перепадами высот до 25 метров, отсутствие транспортной и дорожной инфраструктуры, и вы получите идеальную площадку для максимально объективной проверки возможностей человека и машины. Испытания беспилотных грузовиков «Газпром нефть» и группа компаний «КАМАЗ» сознательно провели именно в таких условиях. Ни нефтяной компании, ни Камскому автозаводу не нужен был образцовый выставочный стенд для демонстрации намерений с одной стороны и возможностей с другой. Никакого глянца, только хардкор: если умные грузовики не потеряют голову при этих вводных, значит, можно смело планировать их внедрение в логистику жизнеобеспечения северных нефтепромыслов. Производитель специально разработал эту серию беспилотников для перевозки грузов в условиях Крайнего Севера и даже назвал ее «Ермак» в честь покорителя Сибири.
В разработке арктических месторождений грузоперевозки играют роль кровеносной системы. С их помощью на удаленные нефтепромыслы поступает «кислород» материально-технических ресурсов для строительства инфраструктуры, добычи нефти, жизнеобеспечения автономных территорий. На Восточно-Мессояхское месторождение, где и проходили первые в истории отечественного автопрома арктические испытания беспилотных КамАЗов, только этой зимой было доставлено более ста тысяч тонн оборудования и материалов. Ежедневно на зимник — 140-километровую временную автодорогу, связывающую автономный промысел с Большой землей, — выходило до 400 машин. Непростой маршрут, включающий десятки ледовых переправ, крутые подъемы и резкие спуски, занимает минимум шесть часов от поселка Тазовский до Восточной Мессояхи. Сегодня компания делает все, чтобы это логистическое плечо было максимально надежным: строит зимники, представляющие собой спрессованный снег со льдом, следит за их обслуживанием, контролирует безопасность перевозок. В какой-то момент стало очевидно, что цифровые технологии, которые «Газпром нефть» сегодня активно использует в разведке и добыче, необходимо внедрять и в логистику, чтобы вывести грузоперевозки на качественно новый уровень безопасности и эффективности.
Ежедневно на зимник — 140-километровую временную автодорогу, связывающую автономный промысел с Большой землей, — выходило до 400 машин. Непростой маршрут, включающий десятки ледовых переправ, крутые подъемы и резкие спуски, занимает минимум шесть часов от поселка Тазовский до Восточной Мессояхи. Сегодня компания делает все, чтобы это логистическое плечо было максимально надежным: строит зимники, представляющие собой спрессованный снег со льдом, следит за их обслуживанием, контролирует безопасность перевозок. В какой-то момент стало очевидно, что цифровые технологии, которые «Газпром нефть» сегодня активно использует в разведке и добыче, необходимо внедрять и в логистику, чтобы вывести грузоперевозки на качественно новый уровень безопасности и эффективности.
Умение передвигаться по заданным маршрутам с высокой точностью, за доли секунды распознавать препятствия и прогнозировать траекторию своего движения — важное преимущество беспилотников
За альфа-КамАЗом
В испытаниях беспилотных КамАЗов на Восточно-Мессояхском месторождении участвовали три машины. Этого количества автомобилей достаточно, чтобы оценить возможность ведущего транспортного средства — КамАЗа-альфы — управлять движением бета-автомобилей в колонне. В перспективе в состав одного грузового каравана могут входить до 20 машин, и каждая будет безоговорочно, если это слово уместно в отношении техники, выполнять приказы альфа-мобиля. Перемещение умных КамАЗов по Мессояхе координировал экипаж из водителя и двух программистов. Они управляли системой контроля за движением колонны и фиксировали результаты эксперимента: даже безлюдные технологии не могут обойтись без людей. Общий километраж испытаний составил 2,5 тысячи километров.
«Как обычный человек представляет себе управление беспилотником? — говорит водитель-испытатель Научно-технического центра „КАМАЗа“ Руслан Муратов. — Прикасаешься к кнопке на приборной панели, и все начинает крутиться, лететь, ехать. По сути, то же самое происходит и у нас. Нажимаем на клавишу автопилота и активации системы на смартфоне, принимаем удобное положение и можем наслаждаться поездкой. На Мессояхе мы так не расслаблялись, конечно: уровень задач и природные условия к релаксу не располагают, нужно каждую секунду быть включенным в процесс».
Принцип работы беспилотных КамАЗов, конечно, сложнее, чем «нажми на кнопку — получишь результат». Программное обеспечение беспилотных транспортных средств разработано по Европейскому стандарту функциональной безопасности ISO 26262. Навигационная спутниковая система позволяет высокоавтоматизированным КамАЗам передвигаться по заданным траекториям с точностью до 20 см. Автомобили оснащены четырьмя типами сенсоров: 3D-лидар строит цифровую карту дорог, 2D-лидар сканирует объекты во фронтальной зоне, радар распознает препятствия на расстоянии до 200 метров, камеры с широкоугольным и узкоугольным объективом фиксируют статичные и движущиеся объекты как в ближней, так и в дальней зоне.
Вся информация с сенсоров и систем связи поступает в мозг машины — вычислитель, где происходит обработка входящих данных и формируются команды для управления автомобилем. Чтобы машины в колонне могли принимать управляющие сигналы и общаться между собой, их оснастили промышленным Wi-Fi, LTE и резервным УКВ на случай, если не сработали другие каналы связи. При проектировании беспилотных КамАЗов было использовано комплексное решение, позволяющее переходить на резервное питание и в случае помех со стороны одного из передающих каналов переключаться на другой. Беспилотники фиксируют информацию от нескольких источников управления и принятия решений. К исполнению принимаются команды блока с наивысшим приоритетом, а в случае отказа системы автомобили получают сигнал к безопасному экстренному торможению. Если осторожно провести аналогию с человеком, то интеллектуальная начинка беспилотников моделирует функции гиппокампа — отдела человеческого мозга, который отвечает за управление реакциями и ориентацию в пространстве.
«Главное преимущество беспилотных транспортных средств — их неограниченная работоспособность, — убежден Дмитрий Потапов, генеральный директор „Газпромнефть-Снабжения“ — предприятия, непосредственно занимающегося доставкой грузов в периметре „Газпром нефти“ и курировавшего испытания. — Эти машины не устают и не ошибаются даже на сложных маршрутах, в условиях низких температур, метелей и плохой видимости. Испытания подтверждают, что в сравнении с пилотируемыми аналогами беспилотные КамАЗы более безопасны и рентабельны».
Умение передвигаться по заданным маршрутам с высокой точностью, за доли секунды распознавать препятствия и прогнозировать траекторию своего движения с учетом актуальной дорожной обстановки — важное преимущество беспилотников. По утверждению разработчиков автоматизированных КамАЗов, использование этих машин позволит на 50% снизить аварийность при грузоперевозках, на 15% уменьшить себестоимость процесса, на 30% увеличить скорость поставок. Для «Газпром нефти», которая главными приоритетами своей работы считает безопасность и эффективность, это серьезные аргументы в пользу внедрения беспилотных технологий в свои логистические процессы.
На законной основе
Развивающийся рынок беспилотных автомобилей — прекрасная возможность для отечественных автопроизводителей вступить в конкурентную борьбу с мировыми гигантами и занять свою нишу. Благо сегодня для этого появляются все условия: и спрос, и законодательная база.
«Несмотря на то что беспилотные технологии — явление сравнительно новое для России, спрос на беспилотные автомобили КамАЗ стал очевидным еще несколько лет назад, и компания давно работает в этой области. Сегодня интерес к внедрению беспилотных перевозок среди промышленных предприятий увеличивается, постепенно формируется законодательная база, это открывает перед нами новые возможности. Уверен, что с решением юридических вопросов, долгое время сдерживавших производство автономного колесного транспорта в стране, тема получит новое развитие», — говорит Ирек Гумеров, заместитель генерального директора КАМАЗа по развитию.
Вадим Яковлев,
заместитель генерального директора по разведке и добыче «Газпром нефти»
Арктические проекты составляют значительную часть нашего производственного портфеля. Мы научились преодолевать вызовы, связанные с экстремальными климатическими условиями и удаленностью наших активов от развитой инфраструктуры, создавая инженерные и технологические решения, которых нет больше нигде в мире. Компания постоянно ищет новые возможности для повышения эффективности и безопасности нефтедобычи. В том числе используя беспилотные технологии мониторинга промышленных объектов и доставки грузов. Эти инновации «Газпром нефть» внедряет вместе с партнерами из других отраслей, создавая стимулы для развития многих российских индустрий.
Россия относительно недавно включилась в мировую гонку беспилотников. И законодательная база для использования высокоавтоматизированных транспортных средств действительно только формируется. В феврале 2020 года Правительство РФ приняло поправки в нормативные документы, упрощающие механизм допуска беспилотных машин на дороги общего пользования и расширяющие географию эксперимента по их тестированию. В числе 13 регионов, включенных в перечень, оказались Югра и Ямал, которые вместе с «Газпром нефтью» вошли в пул инициаторов этих поправок. Кроме того, компания взаимодействует с федеральными органами власти в направлении изменений правил охраны труда при использовании автомобилей на производственных объектах.
На одном треке с нефтяной компанией скорость продвижения инициатив в области развития беспилотных технологий сегодня набирают Сбербанк и «Яндекс». Совместно с отечественными производителями умных машин они подготовили план из 30 технологических и нормативных мероприятий для поэтапного перехода от тестирования к полноценной эксплуатации автоматизированных транспортных средств. Согласно этому документу, направленному в Минтранс и Минпромторг, в 2022 году в стране уже могут быть созданы все условия для полноценной эксплуатации беспилотников.
Беспилотники — на выход
Так или иначе, все российские компании, занимающиеся развитием беспилотных автомобилей, рассчитывают, что их детища появятся на дорогах страны буквально через год-два. Например, представители ГЛОНАССа называют 2022 год как срок окончания эксперимента по тестированию безлюдных технологий. К этому времени «Яндекс» рассчитывает вывести на дороги общего пользования около тысячи умных машин. Сегодня флот беспилотников «Яндекса» насчитывает около 110 автомобилей. Они активно тестируются в Москве и, по утверждению менеджмента компании, технически уже готовы ездить полностью самостоятельно, даже без участия водителя-испытателя. Зеленым светом для выхода таких машин на линию должны стать соответствующие поправки в нормативные акты и ПДД.
Что касается месторождений «Газпром нефти», то первые беспилотные автомобили могут заступить на северную вахту уже в 2021 году. По крайней мере, такое промежуточное решение было принято по итогам испытаний, которые компания провела весной этого года на Южно-Приобском месторождении ХМАО. При поддержке правительства Югры и компании «ГАЗ» — еще одного российского разработчика процессов беспилотного управления транспортом — нефтяники совместно с НПО «Автомобильные интеллектуальные технологии» протестировали беспилотный электромобиль ГАЗель Next Electro и проверили его возможности в решении типовых транспортных задач на внутрипромысловых дорогах.
В ходе испытаний на Южно-Приобском месторождении умная машина фиксировала появление постороннего транспорта и пешеходов, автоматически изменяя скорость и траекторию движения, демонстрировала стабильность связи с центром дистанционного контроля и вообще пришлась нефтяникам по душе: маневренная, быстрая, сообразительная. По итогам тестирования Центр инноваций в логистике «Газпромнефть-Снабжения» направил заводу-производителю уточняющие требования. После учета этих замечаний, возможно, уже ближайшей осенью, на югорском месторождении начнется пробная коммерческая эксплуатация ГАЗель Next Electro с внедрением беспилотника в реальные бизнес-процессы.
«Иногда мне кажется, что я герой фильма о будущем, которое уже наступило», — делится своими мыслями с корреспондентом «СН» водитель-испытатель умных КамАЗов Руслан Муратов. И добавляет: «Но главная роль в этой истории все равно остается за человеком: кто-то же должен принимать правильные решения». Хороший слоган для беспилотного будущего.
Мировой опыт внедрения беспилотников
Дольше остальных занимается автоматизацией перевозок концерн Daimler. Автопроизводитель продемонстрировал самоходный автомобиль под названием Mercedes-Benz Future Truck 2025 еще в 2014 году. Автомобиль использует систему Highway Pilot для навигации по автомагистралям без помощи человека. Компания сосредоточена на перевозках, где грузовики движутся друг за другом, снижая сопротивление воздуха, а также потребление топлива на 10%. Впрочем, у каждого транспортного средства по-прежнему есть водитель: для безопасности и ручного управления после выезда с автотрассы. А самоуправление автомобиля предусмотрено только до скорости 80 км/ч.
Беспилотные мерседесы, ориентированные на езду по автострадам, еще ждут своего часа. В то же время в мае 2019 года стартовала первая по-настоящему беспилотная коммерческая грузовая служба на дорогах общего пользования в Германии. Маршрут, по которому едут грузовики, короткий, а максимальная скорость всего 5 км/ч. Электрические автомобили произведены компанией Einride и не имеют ни кабины водителя, ни обычной системы управления. Они контролируются дистанционно оператором, который может вести до 10 автономных транспортных средств сразу. Грузовики осуществляют перевозки в немецкой логистической компании DB Schenker. Демонтаж кабины снижает эксплуатационные расходы примерно на 60% по сравнению с обычным дизельным грузовиком c водителем, утверждают в Einride.
Не осталась в стороне от актуальной темы и компания Volvo. В 2016 году шведы продемонстрировали беспилотные грузовики с акцентом как на безопасность, так и на эффективность. Ведущий грузовик управляет ускорителями и тормозами двух следующих грузовиков. То есть они все вместе ускоряются и замедляются, тем самым исключая задержки, вызванные временем реакции водителя. Водители все еще имеют доступ к рулевому управлению, но в Volvo говорят, что в будущем вождение тоже может быть автоматизировано.
Компания Volvo, которая сотрудничает с FedEx, утверждает: если управляемые компьютером грузовики следуют друг за другом, экономия топлива может составить 10%. В ноябре 2018 года Volvo Trucks начали первое в мире коммерческое обслуживание грузовиков без водителя, пусть и не на дорогах общего пользования, как Einride. Сервис использует грузовики Volvo в Норвегии для транспортировки известняка из карьера в порт, расположенный в трех километрах от места погрузки.
А вот, пожалуй, самый «громкий» производитель беспилотников компания Tesla пока еще находится в процессе разработки идеального грузовика. Свою первую автоматизированную грузовую модель Tesla представила в ноябре 2017 года. Грузовики оборудованы полуавтоматической системой, где газ, тормоза и руль управляются компьютером на магистралях с четкой разметкой полос, но водитель должен всегда оставаться в полной готовности и с рукой на руле. Цель компании — создание автоматизированных систем, в которых только ведущий грузовик полностью управляется человеком, а остальные следуют за ним.
Пока остаются за рулем и водители беспилотных грузовиков Waymo, компании, более известной как подразделение самоуправляемых автомобилей Google. В марте 2018 года компания объявила о планах по автоматизации грузовых автомобилей и уже через год запустила пилотный проект в Атланте, где автомобили Waymo перевозят грузы в дата-центры Google.
Введение в блок управления и его конструкцию
Введение в блок управления и его конструкцию
Блок управления является частью центрального процессора (ЦП) компьютера, который управляет работой процессора. Он был включен как часть архитектуры фон Неймана Джона фон Неймана. Блок управления отвечает за то, чтобы сообщить памяти компьютера, арифметическому / логическому устройству и устройствам ввода и вывода, как реагировать на инструкции, отправленные процессору.Он извлекает внутренние инструкции программ из основной памяти в регистр инструкций процессора, и на основе содержимого этого регистра блок управления генерирует управляющий сигнал, который контролирует выполнение этих инструкций.
Блок управления работает, получая входную информацию, которую он преобразует в управляющие сигналы, которые затем отправляются в центральный процессор. Затем процессор компьютера сообщает подключенному оборудованию, какие операции выполнять. Функции, выполняемые блоком управления, зависят от типа ЦП, поскольку архитектура ЦП варьируется от производителя к производителю.Примеры устройств, которым требуется CU:
- Управляющие процессоры (ЦП)
- Графические процессоры (ГП)
Функции блока управления —
- Он координирует последовательность перемещения данных в , из множества субблоков процессора и между ними.
- Он интерпретирует инструкции.
- Управляет потоком данных внутри процессора.
- Он принимает внешние инструкции или команды, которые преобразует в последовательность управляющих сигналов.
- Он управляет многими исполнительными модулями (например, ALU, буферами данных и регистрами), содержащимися в ЦП.
- Он также выполняет несколько задач, таких как выборка, декодирование, обработка выполнения и сохранение результатов.
Типы блоков управления —
Есть два типа блоков управления: фиксированный блок управления и микропрограммируемый блок управления.
- Аппаратный блок управления —
В аппаратном блоке управления сигналы управления, которые важны для управления выполнением инструкций, генерируются специально разработанными аппаратными логическими схемами, в которых мы не можем изменить метод генерации сигналов без физического изменения структуры схемы.Код операции инструкции содержит основные данные для генерации управляющего сигнала. В декодере команд декодируется код операции. Декодер команд составляет набор из множества декодеров, которые декодируют различные поля кода операции команды.В результате несколько выходных линий, выходящих из декодера команд, получают значения активных сигналов. Эти выходные линии подключены к входам матрицы, формирующей управляющие сигналы для исполнительных устройств компьютера. Эта матрица реализует логические комбинации декодированных сигналов из кода операции команды с выходами матрицы, которая генерирует сигналы, представляющие последовательные состояния блока управления, и с сигналами, поступающими извне процессора, например.грамм. сигналы прерывания. Матрицы построены аналогично массивам программируемой логики.
Управляющие сигналы для выполнения инструкции должны генерироваться не в единичный момент времени, а в течение всего временного интервала, соответствующего циклу выполнения инструкции. Следуя структуре этого цикла, в блоке управления организована соответствующая последовательность внутренних состояний.
Ряд сигналов, генерируемых матрицей генератора управляющих сигналов, отправляется обратно на входы следующей матрицы генератора управляющих состояний.Эта матрица объединяет эти сигналы с сигналами синхронизации, которые генерируются блоком синхронизации на основе прямоугольных шаблонов, обычно поставляемых кварцевым генератором. Когда новая инструкция поступает в блок управления, блоки управления находятся в начальном состоянии выборки новой инструкции. Декодирование инструкций позволяет блоку управления входить в первое состояние, связанное с выполнением новой инструкции, которое длится до тех пор, пока синхронизирующие сигналы и другие входные сигналы, такие как флаги и информация о состоянии компьютера, остаются неизменными.Изменение любого из ранее упомянутых сигналов стимулирует изменение состояния блока управления.
Это приводит к тому, что для матрицы генератора сигналов управления генерируется новый соответствующий вход. Когда появляется внешний сигнал (например, прерывание), блок управления переходит в следующее состояние управления, которое является состоянием, связанным с реакцией на этот внешний сигнал (например, обработкой прерывания). Значения флагов и переменных состояния компьютера используются для выбора подходящих состояний для цикла выполнения инструкции.
Последними состояниями в цикле являются состояния управления, при которых начинается выборка следующей инструкции программы: отправка содержимого счетчика программ в буферный регистр адреса основной памяти и затем чтение командного слова в регистр команд компьютера. Когда текущая инструкция является инструкцией остановки, завершающей выполнение программы, блок управления переходит в состояние операционной системы, в котором он ожидает следующей пользовательской директивы.
- Микропрограммируемый блок управления —
Фундаментальное различие между этими структурами блока и структурой аппаратного блока управления заключается в существовании управляющего хранилища, которое используется для хранения слов, содержащих закодированные управляющие сигналы, обязательные для выполнения инструкции.В микропрограммных блоках управления последующие командные слова загружаются в регистр команд обычным способом. Однако код операции каждой инструкции не декодируется напрямую, чтобы обеспечить немедленную генерацию управляющего сигнала, но он содержит начальный адрес микропрограммы, содержащейся в управляющей памяти.
- С одноуровневым хранилищем управления:
В этом случае код операции команды из регистра команд отправляется в регистр адреса хранилища управления.На основе этого адреса первая микрокоманда микропрограммы, которая интерпретирует выполнение этой инструкции, считывается в регистр микрокоманды. Эта микрокоманда содержит в своей рабочей части закодированные сигналы управления, обычно в виде нескольких битовых полей. В наборах декодеров полей микрокоманды поля декодируются. Микрокоманда также содержит адрес следующей микрокоманды данной микропрограммы инструкции и поле управления, используемое для управления действиями генератора адресов микрокоманды.Последнее упомянутое поле определяет режим адресации (операция адресации), который будет применяться к адресу, встроенному в текущую микрокоманду. В микрокомандах наряду с режимом условной адресации этот адрес уточняется с помощью флагов состояния процессора, которые представляют состояние вычислений в текущей программе. Последняя микрокоманда в инструкции данной микропрограммы — это микрокоманда, которая извлекает следующую команду из основной памяти в регистр команд.
- С двухуровневым хранилищем управления:
В этом, в блоке управления с двухуровневым хранилищем управления, помимо управляющей памяти для микрокоманд, включена память нано-команд. В таком блоке управления микрокоманды не содержат закодированных сигналов управления. Операционная часть микрокоманд содержит адрес слова в памяти наноинструкций, которое содержит закодированные управляющие сигналы. Память нано-инструкций содержит все комбинации управляющих сигналов, которые появляются в микропрограммах, которые интерпретируют полный набор инструкций данного компьютера, записанный один раз в форме нано-инструкций.Таким образом избегается ненужное сохранение одинаковых рабочих частей микрокоманд. В этом случае слово микрокоманды может быть намного короче, чем с одноуровневым хранилищем управления. Это дает намного меньший размер в битах памяти микрокоманд и, как следствие, гораздо меньший размер всей управляющей памяти. Память микрокоманд содержит элемент управления для выбора последовательных микрокоманд, в то время как эти управляющие сигналы генерируются на основе нано-инструкций.В нано-инструкциях управляющие сигналы часто кодируются с использованием метода 1 бит / 1 сигнала, что исключает декодирование.
- С одноуровневым хранилищем управления:
Вниманию читателя! Не прекращайте учиться сейчас. Ознакомьтесь со всеми важными концепциями теории CS для собеседований SDE с помощью курса CS Theory Course по доступной для студентов цене и подготовьтесь к работе в отрасли.
Рабочий пример: бета-сигналы управления | 13.2 Тематические видео | 13.2 Тематические видео | 13 Создание бета-версии | Вычислительные структуры | Электротехника и информатика
Чтобы лучше понять роль каждого из бета-сигналов управления, мы рассмотрим пример задачи, которая предоставляет нам частично заполненную управляющую таблицу для 5 различных инструкций.
Две из этих инструкций являются существующими бета-инструкциями, которые мы должны вывести из предоставленных управляющих сигналов.
Остальные три — это три новые инструкции, которые мы добавляем в нашу бета-версию, изменяя необходимые управляющие сигналы для обеспечения желаемого поведения каждой из операций.
Первая инструкция, которую мы хотим добавить в нашу бета-версию, — это инструкция LDX, которая представляет собой двойную индексацию загрузки.
Это означает, что для получения эффективного адреса загрузки вместо добавления содержимого регистра к константе, как это делается в инструкции LD, мы складываем содержимое двух разных регистров.
Таким образом, адрес для этой операции загрузки является результатом сложения содержимого регистров Ra и Rb.
Содержимое ячейки памяти, на которую указывает этот эффективный адрес, загружается в регистр Rc.
Наконец, ПК увеличивается на 4, чтобы указать на следующую инструкцию.
Вторая инструкция, которую мы хотим добавить в нашу бета-версию, — это инструкция MVZC, которая является инструкцией с константой перемещения, если она равна нулю.
Эта инструкция работает следующим образом: если содержимое регистра Ra равно нулю, то версия буквальной константы с расширенным знаком будет загружена в регистр Rc.
За этим следует приращение ПК, чтобы указать на следующую инструкцию.
Третья инструкция, которую мы хотим добавить в нашу бета-версию, — это инструкция STR, относящаяся к сохранению.
Для этой инструкции эффективный адрес вычисляется с помощью знака, расширяющего константу C, умножая его на 4 и прибавляя к PC + 4.
Затем содержимое регистра Rc сохраняется в той ячейке памяти, на которую указывает действующий адрес. это было просто вычислено.
В качестве последнего шага ПК увеличивается на 4, чтобы указать следующую инструкцию.
Здесь показано частично заполненное управляющее ПЗУ.
Наша работа — заполнить все желтые поля, помеченные знаком?.
Начнем с верхней строки этой таблицы.
Значение, которое немного отличается в этой строке, — это значение PCSEL, равное 2.
Для большинства инструкций PCSEL равно 0, для инструкций ветвления оно равно 1, а для инструкций JMP равно 2.
Это означает, что инструкция, описанная в этой строке, должна быть инструкцией JMP.
Увеличив масштаб логики управления PCSEL на бета-диаграмме, мы видим, что обычно PCSEL = 0 для перехода к следующей инструкции.
PCSEL = 1, чтобы выполнить операцию ветвления, и PCSEL = 2, чтобы выполнить операцию перехода, где цель перехода указана JT, или цель перехода.
Это означает, что инструкция, описанная в этой строке, должна быть инструкцией JMP.
Здесь показано поведение инструкции JMP.
Эффективный адрес вычисляется путем взятия содержимого RA и очистки нижних 2 битов, чтобы значение стало выровненным по слову.
Адрес следующей инструкции, то есть PC + 4, сохраняется в регистре Rc на тот случай, если нам нужно вернуться к следующей инструкции в программе.
Затем ПК обновляется новым действующим адресом, чтобы фактически продолжить выполнение в месте назначения инструкции JMP.
Эта диаграмма потока данных выделяет необходимый поток данных через бета-версию для правильной реализации инструкции JMP.
Обратите внимание, что через ALU или память не проходят красные линии, потому что ALU и память не используются для этой инструкции.
Управляющие сигналы, которые должны быть установлены, чтобы следовать по этому пути в бета-версии, следующие: WDSEL или выбор записи данных должен быть установлен в 0, чтобы передать значение PC + 4 через мультиплексор WDSEL.
WERF, или файл регистра разрешения записи, должен быть установлен в 1, чтобы разрешить запись в файл регистра.
WASEL, или выбор адреса записи, должен быть установлен в 0, чтобы производить запись в регистр Rc, а не в регистр XP.
ASEL, BSEL и ALUFN не заботятся об инструкции JMP.
Кроме того, MOE, что означает разрешение вывода в память, также не имеет значения, потому что эта инструкция не использует данные памяти.
Единственный управляющий сигнал, связанный с памятью, о котором нам действительно нужно беспокоиться, — это сигнал MWR или чтения записи в память, который должен быть установлен в 0, чтобы в память не записывалось никакое значение.
Возвращаясь к нашему управляющему ПЗУ и заполняя значение WERF, мы видим, что управляющие сигналы для инструкции JMP соответствуют диаграмме потока данных бета-версии, которую мы только что рассмотрели.
Переходя ко второй строке нашего управляющего ПЗУ, мы видим, что теперь в этой строке есть PCSEL = Z.
Это говорит о том, что инструкция, соответствующая этой строке, является своего рода инструкцией ветвления.
Из двух наших инструкций ветвления одна, которая разветвляется при Z = 1, — это BEQ.
Это означает, что эта строка соответствует операции BEQ.
Остальные управляющие сигналы для операции BEQ выглядят так же, как и для JMP, потому что и здесь ALU и память не используются, поэтому единственный сигнал, связанный с ALU и памятью, который должен быть установлен, это MWR, поэтому мы не записать в память.
Кроме того, как и инструкция JMP, инструкции ветвления также сохраняют адрес возврата в регистре Rc, поэтому поведение управляющих сигналов, относящихся к регистровому файлу, одинаково.
Теперь посмотрим на третью строку ПЗУ управления.
В этой строке нам фактически сообщают, что соответствующая инструкция является недавно добавленной инструкцией LDX.
Итак, наша задача — определить, как установить отсутствующие управляющие сигналы, чтобы добиться желаемого поведения для этой операции.
Напомним, что ожидаемое поведение этой инструкции состоит в том, что содержимое регистров Ra и Rb будет сложено вместе, чтобы получить эффективный адрес загрузки.
Это означает, что нам нужно выполнить ADD в качестве нашего ALUFN.
Нам также нужны нулевые значения ASEL и BSEL для передачи значений регистров Ra и Rb в ALU.
Здесь показан полный поток данных через регистровый файл, ALU и память.
Чтобы читать регистр Rb, а не Rc, RA2SEL должен быть установлен в 0.
Как мы только что упомянули, ASEL и BSEL установлены в 0, а ALUFN установлен в ADD.
Результат сложения регистров Ra и Rb используется как адрес загрузки.
Это называется MA, или адресом памяти на бета-диаграмме.
Чтобы разрешить чтение из памяти, мы устанавливаем MWR на 0 и MOE на 1.
Это устанавливает функцию чтения / записи для чтения и позволяет считывать вывод из порта чтения памяти.
На бета-диаграмме считанные данные помечены как MRD или данные чтения из памяти.
Данные, которые считываются из памяти, затем передаются в регистровый файл, устанавливая WDSEL = 2.
Чтобы записать этот результат в регистр Rc, WERF = 1 и WASEL = 0.
Итак, здесь показано законченное управляющее ПЗУ для операции LDX.
Переходим к четвертой инструкции.
Здесь мы видим, что ALUFN просто пропускает операнд B через регистровый файл.
Мы также видим, что WERF зависит от значения Z.
Это означает, что инструкция, которая соответствует этой строке, — это MVZC, которая перемещает константу в регистр Rc, если содержимое регистра Ra = 0.
Способ, которым это Инструкция работает так: BSEL = 1 для передачи константы в качестве операнда B и ALUFN = B для передачи этой константы через ALU.
WDSEL = 1, так что выход ALU возвращается как значение записи для файла регистров.
Поскольку WDSEL = 1, а не 2, мы знаем, что данные, поступающие из памяти, будут игнорироваться, поэтому MOE может быть безразличным.
Конечно, MWR все равно должен быть установлен в 0, чтобы гарантировать, что мы не записываем случайные значения в нашу память.
RA2SEL также не имеет значения, потому что нас не волнует, передается ли регистр Rb или регистр Rc в качестве второго аргумента чтения файла регистра, RD2.
Причина, по которой нам все равно, состоит в том, что BSEL = 1 будет игнорировать значение RD2 и передавать константу, которая поступает непосредственно из инструкции после ее расширения знаком.
ASEL также не имеет значения, потому что ALU будет игнорировать вход A, когда ALUFN = B.
WASEL должен быть 0, чтобы результат операции записывался в регистр Rc.
Наконец, PCSEL = 0 для загрузки PC + 4 в регистр PC, чтобы следующая инструкция была выбрана после этой.
Теперь мы на последней строке нашего управляющего ПЗУ.
Мы знаем, что эта строка должна соответствовать нашей третьей добавленной инструкции, которая является STR или относительной записью.
Напомним, что эта инструкция записывает содержимое регистра Rc в память по адресу, который вычисляется эффективной адресной строкой.
Эффективный адрес этой инструкции — PC + 4 + 4 * SEXT (C).
Дополнительный сумматор, расположенный непосредственно под памятью команд, используется для вычисления PC + 4 + 4 * SEXT (C).
Это значение затем передается в ALU через операнд A путем установки ASEL = 1.
Установка ALUFN = A передает это значение как выход ALU, чтобы использовать его в качестве адреса памяти.
Это адрес, по которому хранилище будет записывать в память.
Значение, которое будет записано по этому адресу в памяти, — это содержимое регистра Rc.
Регистр Rc пропускается через регистровый файл, устанавливая RA2SEL = 1.
Это заставляет RD2 иметь содержимое регистра Rc.
Это значение затем становится MWD или данными записи в память, которые являются данными, которые будут храниться в адресе памяти, созданном ALU.
Чтобы разрешить запись в память, MWR должен быть установлен на 1.
Поскольку WERF = 0, ничего нельзя записать в регистровый файл.
Это означает, что значение WDSEL и WASEL не имеет значения, поскольку файл регистров не будет затронут независимо от их значений.
Наконец, ПК увеличивается на 4, чтобы получить следующую инструкцию.
Итак, здесь показано наше законченное контрольное ПЗУ для операции STR.
Аналоговые управляющие сигналы, используемые в системах отопления, вентиляции и кондиционирования воздуха
В старые времена систем автоматизации зданий управление большинством вещей осуществлялось с помощью сжатого воздуха. Этот метод назывался пневматическим и состоял из системы с воздушным компрессором с небольшими трубками, проложенными по всему зданию, с использованием воздуха низкого давления в диапазоне 3-15 фунтов на квадратный дюйм. Система управления могла либо включать, выключать подачу воздуха к устройству, либо изменять давление воздуха на устройство в зависимости от нагрузки.Эти маленькие трубки будут управлять клапанами, заслонками и насосами, среди прочего, в системе. Изменение сигнала с нагрузкой — это то, что мы будем называть модулирующим аналоговым сигналом.
Положительные и отрицательные стороны каждого типа аналогового управляющего сигнала
Со времен расцвета пневматики электронные средства управления стали менее дорогими и более популярными. Сегодня в системе автоматизации здания почти все управляется электроникой. Модулирующие аналоговые сигналы теперь представляют собой либо переменное напряжение 0-10 вольт постоянного тока, либо переменный ток 4-20 миллиампер постоянного тока.Давайте посмотрим на плюсы и минусы каждого типа этих аналоговых сигналов.
Сигнал 0-10 В постоянного тока
Запуск с сигналом 0–10 В постоянного тока, очень распространенным в отрасли HVAC, и большинство контроллеров и оборудования управления зданием могут отправлять и принимать сигнал 0–10 В постоянного тока. Этот сигнал чувствителен к электрическим помехам от двигателей и других линий электропередач и оборудования в здании. Длина кабеля также играет роль в сигнале. Более длинные кабели могут эффективно снизить напряжение сигнала из-за сопротивления длины провода.Чем длиннее кабель, тем больше падение напряжения в сигнале.
Поиск и устранение неисправностей 0–10 В постоянного тока можно легко выполнить, используя вольтметр постоянного тока и подключив провода измерителя к клеммам, на которых они подсоединены. Если счетчик показывает ноль вольт, это не означает, что контроллер не выдает напряжение, это может означать, что в проводе есть обрыв. Вы должны перейти к другому концу провода и снова измерить напряжение, чтобы определить, не оборван ли провод.
Сигнал 4-20 мА
Сигнал 4–20 мА — лучший выбор для кабелей большой длины, а также он менее восприимчив к внешним помехам от двигателей и других линий электропередач и оборудования в здании.По этим причинам сигнал 4-20 мА использовался в управлении промышленными процессами.
Устранение неисправностей также легко выполняется с помощью амперметра постоянного тока. Чтобы использовать амперметр постоянного тока, вы сначала должны разорвать токовую цепь, отсоединив один из проводов от точки подключения и надев один провод измерителя на точку подключения, а другой провод измерителя — к проводу, удаленному от точки подключения. Поскольку «минимальный» сигнал составляет 4 мА, легко определить, есть ли обрыв провода в контуре, поскольку счетчик покажет 0 мА.
Таким образом, у каждого типа управляющего сигнала есть свои плюсы и минусы. Оба типа могут быть легко измерены техническим прибором, если он может считывать постоянное напряжение постоянного тока в мА. Вы можете использовать любой из этих типов в системах HVAC и должны владеть обоими методами.
Заявление об ограничении ответственности: R. L. Deppmann и его аффилированные лица не несут ответственности за проблемы, вызванные использованием информации на этой странице. Хотя эта информация исходит из многолетнего опыта и может быть ценным инструментом, она может не учитывать особые обстоятельства в вашей системе, и поэтому мы не можем нести ответственность за действия, вытекающие из этой информации.Если у Вас возникнут вопросы, обращайтесь к нам.
Раздел 544.007 — Сигналы управления дорожным движением в целом, Tex. Transp. Кодекс § 544.007
Действующий с законодательством, принятым на регулярной сессии 2019 года
Раздел 544.007 — Сигналы управления дорожным движением в целом (a) Сигнал управления дорожным движением, отображающий различные цветные огни или цветные светящиеся стрелки последовательно или в комбинации, может отображаться только зеленым , желтый или красный и применяется к операторам транспортных средств, как это предусмотрено в этом разделе. (b) Оператор транспортного средства, стоящего перед круговым зеленым сигналом, может двигаться прямо или повернуть направо или налево, если только знак не запрещает поворот. Оператор должен уступить дорогу другим транспортным средствам и пешеходам, законно находящимся на перекрестке или прилегающем пешеходном переходе, когда подан сигнал. (c) Оператор транспортного средства встречает сигнал зеленой стрелки, отображаемый отдельно или с другим сигналом, может осторожно въехать на перекресток, чтобы двигаться в направлении, разрешенном стрелкой или другим указателем, показанным одновременно.Оператор должен уступить дорогу пешеходу на прилегающем пешеходном переходе на законных основаниях и другим транспортным средствам, законно использующим перекресток. (d) Оператор транспортного средства, который видит только постоянный красный сигнал, должен остановиться на четко обозначенной стоп-линии. При отсутствии стоп-линии оператор должен остановиться перед въездом на пешеходный переход на ближней стороне перекрестка. Автомобиль, который не поворачивает, должен стоять до тех пор, пока не появится указание на движение. После остановки и остановки до перекрестка, где можно безопасно въехать на перекресток и предоставления пешеходам законного права проезда на соседнем пешеходном переходе и других транспортных средств, законно использующих перекресток, оператор может: (1) повернуть направо; или (2) повернуть налево, если пересекающиеся улицы являются улицами с односторонним движением и левый поворот разрешен. (e) Водитель транспортного средства, движущийся по постоянному желтому сигналу, предупреждается этим сигналом о том, что: (1) движение, разрешенное зеленым сигналом, прекращается; или (2) подается красный сигнал. (f) Транспортная комиссия Техаса, муниципальный орган или уполномоченный суд округа могут запретить в пределах юрисдикции организации поворот для оператора транспортного средства, стоящего перед постоянным красным сигналом, разместив на перекрестке уведомление о том, что поворот запрещенный. (g) Этот раздел применяется к официальному сигналу управления дорожным движением, размещаемому и поддерживаемому в месте, отличном от перекрестка, за исключением положения, которое по своей природе не может применяться. Требуемая остановка должна производиться у знака или разметки на тротуаре, указывающих, где должна быть сделана остановка. При отсутствии такого знака или обозначения остановка должна производиться по сигналу. (h) Обязанности, налагаемые настоящим разделом, применяются к водителю трамвая так же, как и к водителю транспортного средства. (i) Оператор транспортного средства, столкнувшегося с сигналом управления движением, отличным от сигнала управления съездом на автомагистраль или пешеходного гибридного маяка, который не отображает индикацию ни в одной из сигнальных головок, должен остановиться в соответствии с разделом 544.010 как будто на перекрестке стоит знак остановки. (j) В этом разделе: (1) «Сигнал управления съездом на въезд с автострады» означает сигнал управления движением, который управляет потоком движения, въезжающим на автостраду. (2) «Гибридный пешеходный маяк» означает управляемый пешеходом сигнал управления дорожным движением, который последовательно отображает огни разного цвета только при активации пешеходом.Tex. Transp. Кодекс § 544.007
с изменениями, внесенными законами 2011 г., 82-й лег., Р.С., гл. 485, п. 1, эфф. 17 июня 2011 г. с изменениями, внесенными законами 2003 г., 78-й лег., Гл. 1325, п. 19.04, эфф. 1 сентября 2003 г., Закон 1995 г., 74-й лег., Гл. 165, п. 1, эфф. 1 сентября 1995 г.Структура для диагностики неконтролируемых сигналов в многомерном процессе с использованием оптимизированных опорных векторных машин
Многомерное статистическое управление процессом является продолжением и развитием унитарного статистического управления процессом.Большинство многомерных диаграмм статистического контроля качества обычно используются (в обрабатывающей промышленности и сфере услуг), чтобы определить, работает ли процесс так, как задумано, или есть какие-то неестественные причины отклонений в общей статистике. Как только контрольная диаграмма обнаруживает неконтролируемые сигналы, одна трудность, с которой сталкиваются с многомерными контрольными диаграммами, — это интерпретация неконтролируемого сигнала. То есть мы должны определить, одна или несколько переменных или их комбинация ответственны за аномальный сигнал.В этой статье описан новый подход к диагностике неконтролируемых сигналов в многомерном процессе. Предлагаемая методология использует оптимизированные машины опорных векторов (классификация опорных векторов машин на основе генетического алгоритма) для распознавания набора подклассов многомерных паттернов, определения ответственных переменных при возникновении паттернов. Для проверки этой модели используются несколько наборов экспериментов. Эффективность предлагаемого подхода демонстрирует, что эта модель может точно классифицировать источник (источники) неконтролируемого сигнала и даже превосходит традиционную многомерную схему управления.
1. Введение
Статистическое управление процессами (SPC) — один из наиболее эффективных инструментов общего управления качеством (TQM), который используется для отслеживания изменений производственного процесса. Контрольные диаграммы — это наиболее широко применяемые инструменты SPC, используемые для выявления аномальных вариаций контролируемых измерений, а также для определения их возможных причин [1, 2]. По диаграмме состояния мы можем легко узнать, находится ли производственный процесс в контролируемом состоянии или нет; Специалисты по качеству или инженеры ищут возможные причины и вносят некоторые необходимые исправления и корректировки, чтобы вернуть неконтролируемый процесс обратно в контролируемое состояние [3].
В поле множественной диагностики качества часто есть две или более характеристики качества, которые следует контролировать одновременно. Идея природы заключается в том, что мы можем вести отдельную контрольную диаграмму для каждой характеристики. Традиционная технология SPC основана на данных наблюдения за процессом, отвечающих независимым и одинаково распределенным. Однако многие производственные процессы не соответствуют этому предположению. Это привело бы к явлению высокой степени распознавания ошибок, когда характеристики сильно коррелированы.Хотеллинг первым распознает дефекты, если мы просто расширим одномерную контрольную диаграмму до многомерного процесса; таким образом, концепция многомерного качества была предложена в 1947 году. Статистика Хотеллинга [4–7] может быть наиболее распространенным инструментом в многомерном анализе для определения того, находится ли весь процесс в неконтролируемом состоянии. Основные возможные причины средних сдвигов связаны с появлением новых рабочих, машин, материалов или методов, изменением метода или стандарта измерения и т. Д.Статистикой теста среднего вектора учитывается не только волатильность среднего, но и корреляция между переменными. это оптимальная тестовая статистика для обнаружения общего сдвига. Помимо контрольной диаграммы, Mason et al. [8] предложили процедуру выбора причины с использованием декомпозиции статистики. Пользователь может увидеть вклад каждой переменной, разложив статистику. Более того, это разложение позволяет пользователю наблюдать, какая переменная (и) со значительным вкладом является (являются) причиной аномальных процессов.Недостатками этого метода являются дополнительные вычисления и его чувствительность к количеству переменных. Для обнаружения средних сдвигов были предложены другие многомерные контрольные диаграммы, такие как контрольная диаграмма многомерного экспоненциально взвешенного скользящего среднего (MEWMA) и контрольная диаграмма многомерной совокупной суммы (MCUSUM). Lowry et al. [9] предложили многомерное расширение контрольной диаграммы экспоненциально взвешенной скользящей средней (EWMA). Они сравнили свой метод с контрольной диаграммой многомерной совокупной суммы (MCUSUM), основанной на показателях средней длины бега (ARL), и их результаты показали, что диаграмма MEWMA была похожа на диаграмму MCUSUM в обнаружении средних сдвигов многомерного нормального распределения.
Помимо традиционной технологии многомерного статистического управления процессом (MSPC), многие ученые пытались диагностировать аномальный процесс в многомерном процессе с помощью интеллектуального анализа данных и искусственного интеллекта, особенно нейронных сетей [10, 11]. Нейронные сети (NN) обладают отличной устойчивостью к шуму в реальном времени, не требуя гипотез о статистическом распределении контролируемых измерений. Эти важные особенности делают сети NN перспективными и эффективными инструментами, которые можно использовать для улучшения анализа данных в приложениях для контроля качества производства.В последние два десятилетия различные сети с разной структурой и алгоритмами обучения получили широкое распространение для контроля качества [12]. Многослойный персептрон (MLP) NN [13], обучающее векторное квантование (LVQ) NN [14], вероятностное NN [15], адаптивная теория резонанса (ART) NN [16], модульная NN [17], NN с обратным распространением (BPN) [ 18] и т. Д., Использовались для обнаружения аномальных сигналов и (или) идентификации некоторых основных аномальных паттернов, таких как сдвиг, тренд, цикл и паттерны смешения. Эти модели на основе NN показали свою эффективность и действенность в SPC.
Суммирование нескольких интересующих переменных в одной статистике не освобождает источник (и) неконтролируемых сигналов; то есть, он не может сказать, какая из переменных или комбинация переменных вызвали неконтролируемые сигналы. Вы знаете, что знание разделения неконтролируемых переменных может быть полезным для сужения набора возможных назначаемых причин, что является более быстрым выявлением конкретных причин и сокращением затрат на корректировку.
В литературе есть несколько многомерных исследований, посвященных нейронным сетям, таких как эффективное обнаружение неконтролируемых сигналов или идентификация источников неконтролируемых сигналов посредством среднего сдвига в многомерных процессах.Эль-Мидани и др. [19] разработали искусственные нейронные сети для распознавания, управляющие распознаванием образов диаграммы в многомерном процессе. Yu et al. [1, 20] предложили подход к ансамблю селективной нейронной сети (NN) (DPSOEN, оптимизация роя дискретных частиц) для мониторинга и диагностики неконтролируемых сигналов в двумерном процессе. Обширные эксперименты показывают, что этот метод эффективен. Салехи и др. [21] представили гибридную модель, основанную на обучении, для оперативного анализа неконтролируемых сигналов в многомерных производственных процессах.Основным вкладом этой работы является распознавание типа неестественного паттерна и классификация основных параметров для сдвига, тренда и цикла, а также для каждой переменной одновременно с помощью предложенной гибридной модели. Kim et al. [22] попытались интегрировать современные алгоритмы интеллектуального анализа данных, включая искусственные нейронные сети, поддержку векторной регрессии и многомерные сплайны адаптивной регрессии с методами SPC для достижения эффективного мониторинга в многомерных и автокоррелированных процессах.Результаты моделирования для различных сценариев показали, что контрольные диаграммы на основе моделей интеллектуального анализа данных работают лучше, чем традиционные контрольные диаграммы на основе моделей временных рядов. Cheng et al. [23] разработали использование SVR для прогнозирования величины изменения процесса. Нейронные сети с прямой связью с различными алгоритмами обучения и оценкой на основе CUSUM используются в качестве эталонов для сравнения.
Исследования показывают, что определение источника (ов) неконтролируемых сигналов с помощью нейронной сети оказалось эффективным и полезным инструментом в многомерных производственных процессах, который имеет лучшие возможности оценки, чем CUSUM и MEWMA.Однако классификатор ИНС обладает способностью к суждению и классификации только после того, как он изучен с помощью машинного обучения. Это обучение, основанное на принципе минимизации эмпирического риска, что приводит к длительному времени обучения, плохой способности к обобщению и легкости падения в локальный минимум. Он не подходит для качественной диагностики, когда процесс динамичный и изменчивый. Хотя машины поддержки векторов показали отличную производительность обобщения в ряде приложений, одна проблема, с которой сталкивается пользователь SVM, заключается в том, как выбрать ядро и конкретные параметры для этого ядра.Поэтому приложения SVM требуют поиска оптимальных настроек для конкретного приложения. Функции ядра отображают исходные данные в пространство более высокого измерения и делают входные данные линейно разделяемыми в преобразованном пространстве. Выбор функций ядра в значительной степени зависит от задачи и является наиболее важным фактором в приложениях поддержки векторных машин. В этой работе ядро RBF используется в качестве функции ядра SVM, поскольку оно имеет тенденцию обеспечивать лучшую производительность.
В этом исследовании, учитывая высокую мощность распознавания машины опорных векторов и возможности глобального поиска генетического алгоритма, был разработан оптимизированный подход SVM, названный GA-SVM (классификация опорных векторов машин на основе генетических алгоритмов); Предложена структура распознавания образов контрольной диаграммы многомерных данных наблюдений для классификации источников неконтролируемых сигналов в многомерных процессах. Классификация SVM используется для распознавания выбранных подклассов многомерных аномальных паттернов, определения вариации (ов), которые ответственны (являются) за возникновение анормального паттерна, в то время как роль GA заключается в том, что он оптимизирует параметры SVM, такие как параметры функции ядра. и штрафной коэффициент.
Остальная часть этого документа организована следующим образом: генерация шаблонов многомерного процесса и алгоритмы опорных векторных машин представлены в разделе 2; Раздел 3 описывает диагностический классификатор SVM на основе ГА в средстве процесса для его содержания; в разделе 4 мы используем численный пример и серийные тесты для проверки предложенного метода; выводы представлены в Разделе 5.
2. Методология
В этом разделе представлен практический обзор создания шаблонов многомерных процессов и алгоритмов поддержки векторных машин.Он готовится к тому, чтобы модель диагностики была предложена в следующей главе.
2.1. Генерация шаблонов многомерного процесса
Согласно теории многомерного контроля качества [24–26], статистика может отражать состояние корреляционной структуры и средний вектор данных многомерного процесса. Общее качество многомерного процесса можно контролировать, сравнивая приведенную выше статистику с положительным UCL. Эти диаграммы легко построить, если параметры процесса (т.е., — средний вектор и — ковариационная матрица) известны. Однако ковариационная матрица обычно неизвестна во многих областях контроля качества; мы не могли принять значение произвольно. В этом случае ковариационная матрица должна оцениваться с помощью предельной выборки. Вектор среднего и ковариационная матрица достаточны для характеристики любого многомерного нормального распределения. Таким образом, случайные многомерные векторы, такие как, представляют собой вектор наблюдений на основе качественных характеристик независимых нормальных распределений во времени.Таким образом, при многомерном статистическом управлении процессом средний вектор статистики получается с использованием следующей формы:
Случайные выборки размера регулярно собираются из процесса. Таким образом, представляет собой средний вектор для каждого из многомерных векторов, например для to. Термин представляет собой количество характеристик качества, представленных одним вектором-столбцом, и является транспонированным, то есть вектором-строкой. Наконец,, которая является матрицей по, является обратной по отношению к матрице. Следовательно, статистика является результатом матрицы по (т.е., это скалярная величина). Каждый нормальный многомерный средний вектор должен приводить к значению, которое меньше или равно UCL, заданному как, где — верхний хвост распределения, который действует как ошибка типа I, когда доверительный предел равен проценту и со степенями свободы. . Любой вектор, который приводит к построению графика выше предела, исключается из моделируемого набора данных. Размер выборки сохраняется равным 1, так что векторное значение каждой моделируемой многомерной точки используется непосредственно для представления одного наблюдения выборки.
2.2. Краткое введение в алгоритмы машины опорных векторов
Метод машины опорных векторов — это новая и многообещающая технология классификации и регрессии [27–31]. Основную идею SVM можно кратко изложить следующим образом. SVM изначально отображает входные векторы в многомерное пространство признаков, линейно или нелинейно, что имеет отношение к выбору функции ядра. Входные векторы или векторы признаков в пространстве признаков затем классифицируются линейно с помощью численно оптимизированной гиперплоскости, разделяющей два класса (это может быть расширено до мультикласса).Обучение SVM всегда ищет глобально оптимизированное решение, а гиперплоскость зависит только от подмножества обучающих примеров [32–35].
Позвольте,,, быть обучающим набором с входными векторами и выходом. Здесь — количество выборочных наблюдений, — размерность каждого наблюдения и — известная цель. Алгоритм заключается в поиске гиперплоскости, где — вектор гиперплоскости и член смещения, чтобы отделить данные от двух классов с максимальной шириной поля, а все точки под границей называются опорным вектором.Для оптимизации гиперплоскости SVM решает следующую задачу оптимизации:
Трудно решить (2). Таким образом, SVM преобразует задачу оптимизации в двойственную задачу методом Лагранжа. Значение в методе Лагранжа должно быть неотрицательными действительными коэффициентами. Уравнение (2) преобразуется к следующей ограниченной форме:
В (3) — коэффициент штрафа, определяющий степень штрафа, назначенного за ошибку. Его можно рассматривать как параметр настройки, который можно использовать для управления компромиссом между максимизацией маржи и ошибкой классификации.Чтобы точно разделить два класса, добавьте как недостающую переменную в уравнение Лагранжа, чтобы получить,,. Задача переменной slack — увеличить гибкий буфер границы.
В общем, он не смог найти линейную отдельную гиперплоскость для всех данных приложения. Для задач, которые не могут быть линейно разделены во входном пространстве, SVM использует метод ядра для преобразования исходного входного пространства в многомерное пространство признаков, где может быть найдена оптимальная линейная разделяющая гиперплоскость.Общие функции ядра — это линейная, полиномиальная, радиальная базисная функция (RBF) и сигмоид. Хотя доступно несколько вариантов функции ядра, наиболее широко используемой функцией ядра является RBF, которая определяется как [36] где — параметр функции ядра. Следовательно, в этом исследовании используется RBF. Также в этом исследовании мы использовали многоклассовый метод SVM для построения диагностической модели.
3. Модель диагностики на основе оптимизированной машины опорных векторов в процессе
Параметры, которые необходимо определить, — это параметр ядра, параметр регуляризации и.Параметр ядра определяет структуру многомерного пространства функций. Параметр ядра выбирается с помощью генетического алгоритма (GA). Параметр регуляризации следует выбирать с осторожностью, чтобы избежать переобучения.
В этой статье для достижения цели диагностики по среднему вектору, а также идентификации и определения местоположения аномальных переменных в многомерном процессе, во-первых, мы предполагаем, что аномальные факторы в процессе только делают изменяемые средний вектор вместо изменяемой ковариационной матрицы.Исходя из этого, в данной статье предлагается диагностика неконтролируемых сигналов в многомерном процессе на основе диаграммы хотеллинга и оптимизированных векторных машин поддержки. Структура модели диагностики кратко проиллюстрирована на рисунке 1.
Схема может быть кратко представлена следующим образом: часть обнаружения и процесс диагностики. Когда статистически выявляется неконтролируемый сигнал, собираются дополнительные наблюдения процесса, и они рассматриваются как хромосома, которая затем выполняется с помощью двоичного кода.Мультиклассовый машинный классификатор опорных векторов будет использоваться для распознавания случайной хромосомы, а точность распознавания будет рассматриваться как функция пригодности для оценки приспособленности отдельного признака. Путем операций отбора, кроссовера и мутации с самоадаптирующейся оптимизацией GA для параметра штрафа и параметра ядра мы получаем оптимальную модель, которая, наконец, используется для идентификации источника (ов) неконтролируемого сигнала, а также идентификация и расположение аномальных переменных.
На рисунке 1 мы идентифицируем и обнаруживаем аномальные переменные, переводя их в проблему распознавания образов. Для процесса производства размерности есть случаи: среднее значение каждой переменной либо нормальное, либо ненормальное. В этих условиях средний вектор -мерности полностью имеет нормальные (ненормальные) состояния. Другими словами, существует только одно нормальное состояние и ненормальное состояние. Если контрольная диаграмма вышла из-под контроля, это должно быть одно из ненормальных состояний. Чтобы различать эти состояния, мы определяем это ненормальное состояние как шаблоны, которые следует идентифицировать; мы используем оптимизированную модель SVM для выявления аномального сигнала, полученного с помощью генетического алгоритма.
В качестве примера двумерного процесса опорный вектор среднего и ковариационная матрица; аномальное состояние среднего вектора имеет только три обстоятельства, которые следует идентифицировать: первая переменная вышла из-под контроля, а вторая переменная находится под контролем; первая переменная находится под контролем, вторая переменная вышла из-под контроля; обе две переменные вышли из-под контроля. Если обозначить неконтролируемую переменную как 1, а контролируемую переменную как 0, то целевыми векторами для этих случаев были значения (0,0,0,0), (0,1,0,0), (0 , 0,1,0) и (0,0,0,1), которые используются для идентификации того, что нормальная, первая и вторая или обе характеристики качества находятся в неконтролируемом состоянии, где отметка ( 0,0,0,0) представляет собой нормальные шаблоны, а (0,1,0,0), (0,0,1,0) и (0,0,0,1) представляют три аномальных шаблона.Когда по статистике обнаруживается неконтролируемый сигнал, и если оптимальная модель SVM обнаруживает шаблон сигнала (0,1,0,0), это указывает на то, что в этом процессе первая переменная находится под контролем, а вторая переменная выходит из-под контроля; Как только оптимальная модель SVM обнаруживает шаблон сигнала (0,0,0,1), это указывает на то, что в этом процессе обе две переменные вышли из-под контроля, и так далее. В упомянутой выше идее оптимальная модель SVM является не только заменой контрольной диаграммы хотеллинга, но также идентификацией и местоположением аномальных переменных, когда контрольной схемой обнаруживается неконтролируемый сигнал.
4. Моделирование и анализ
В этом разделе приведен пример, полученный из двумерного примера химического процесса Монтгомери, чтобы проиллюстрировать использование предлагаемого подхода. Параметры этого процесса представляют собой целевые значения процесса и; вектор эталонного среднего и эталонная матрица дисперсии получают по первым пятнадцатым данным наблюдения. Таким образом, и is
В следующей части мы сравним возможности оценки различных статистических подходов, таких как BPNN, SVM и оптимизированная SVM.
4.1. Разработка примеров и установка параметров
Данные обучения очень важны в приложениях SVM, которые определяют эффективность распознавания работы классификатора. В этом исследовании метод моделирования Монте-Карло был применен для создания необходимых наборов данных нормальных и ненормальных примеров для обучения и тестирования. Многомерное моделирование может дать только упрощенную картину реальности. Наилучшая альтернатива — там, где это возможно, собирать различные данные из реальных производственных систем.
В двумерном приложении SPC вход в нейронную систему должен состоять из окна временного ряда двумерных векторов. В этом исследовании рассматриваются пять различных типов сдвигов (т. Е., И), связанных с той характеристикой качества, которые равномерно охватывают диапазон сдвигов всего процесса. Для создания наборов обучающих данных мы сдвигаем средний вектор как, и в этом двумерном процессе, чтобы проверить хорошие возможности SVM в небольшой выборке; пятьсот входных векторов сдвинуты на 1.0 для каждой аномальной модели были сгенерированы с использованием статистики, которая использовалась в качестве набора обучающих данных для оптимизированной SVM.
Количество SVM в выходном слое определяется размерностью характеристик качества. Выходной вектор состоит из четырех элементов и использует наибольшее значение для идентификации источника (ов) всех сигналов; в этом исследовании количество выходных узлов равно 4.
Чтобы оценить производительность оптимизированной SVM, были сгенерированы различные сдвинутые вектора выборки,,, и.Подобно сгенерированным наборам обучающих данных, мы применили статистику для обнаружения общего неконтролируемого сигнала для каждого вектора выборки с ошибкой типа I, равной 0,5. Мы делали это, пока не получили 500 примеров для каждого ненормального случая, которые использовались в качестве наборов данных тестирования оптимизированной SVM.
4.2. Оптимизация с использованием генетического алгоритма (GA)
SVM — это мощный инструмент машинного обучения и интеллектуального анализа данных, обладающий классификационной способностью. Однако на производительность SVM сильно влияет параметр штрафа (стоимости) и дисперсия параметра функции ядра RBF.
Глобальная оптимизация пытается найти абсолютно лучший набор оптимальных условий, которые приводят к наивысшему объективному значению. Обычно это очень сложная проблема. Традиционные методы оптимизации, такие как поиск градиентного подъема / спуска в направлении локального вектора градиента, и, таким образом, легко застревают в проблеме с мультимодальной целевой функцией. Метод оптимизации, используемый в нашем исследовании, — это генетический алгоритм (ГА), который является одним из самых популярных и широко используемых методов глобальной оптимизации.На рисунке 2 представлена структура оптимизации параметров с помощью генетического алгоритма (ГА).
4.3. Анализ производительности для двумерного процесса
В этом разделе влияние ключевых факторов оптимизированной модели SVM на их производительность обобщения анализируется путем проведения следующих экспериментов. Анализ может помочь нам получить подходящую настройку параметров для улучшения обобщающих характеристик предлагаемой модели.
4.3.1. Тест 1: процесс выбора оптимальных параметров
В этом исследовании свободные параметры SVM были выбраны после эксперимента по оптимизации генетического алгоритма. Весь процесс реализован в Matlab 2009b. Чтобы найти оптимальные параметры, мы выбрали типы сдвига для трех различных значений волатильности; каждый тип генерирует 100 образцов. Соответствующие параметры генетических операций устанавливаются следующим образом: размер популяции — 20, максимальное количество итераций — 200, генетический разрыв поколения и вероятность мутации принимаются равными 0.9 и 0,01 соответственно, сингл — 0,01, выбранное ядро было основано на RBF с размером 1,0834, а параметр регуляризации был установлен на 1,5136. На рисунках 3 (a) и 3 (b) показан пример результата поиска по сетке, где -axis и -axis равны и, соответственно. -Axis — это точность. Результаты этого эксперимента показали, что SVM довольно устойчива к выбору параметров.
(a) Поверхностный график поиска по сетке
(b) Контурные графики поиска по сетке
(a) Поверхностный график поиска по сетке
(b) Контурные графики поиска по сетке
4.3.2. Тест 2: Анализ чувствительности к разным моделям
В таблице 1 представлено сравнение производительности модели BPNN на основе исходных данных, модели SVM и оптимизированной модели SVM, обученной и протестированной с использованием исходных данных. Общий общий процент правильного распознавания трех моделей составляет 92,11, 94,23 и 97,96 соответственно. Оптимизированная SVM показывает лучшую производительность идентификации в большинстве случаев по сравнению с моделью BP и SVM. Это указывает на то, что тип классификатора и выбор ядерного параметра и параметра штрафа (стоимости) могут помочь повлиять на качество распознавания классификации.Таким образом, генетический алгоритм может усилить характерную черту неконтролируемых сигналов.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4.3.3. Тест 2: Анализ чувствительности к количеству обучающих примеров
Обучающие наборы разных размеров были созданы для оптимизации обучения.В таблице 2 представлены результаты тестирования оптимизированной SVM, обученной на различных примерах. Из этих результатов можно сделать следующие выводы: (1) Увеличение количества обучающих примеров может улучшить производительность GASVM до определенного уровня точности при любом заданном значении величины сдвига. Это можно объяснить тем фактом, что с достаточно большими обучающими наборами есть больше шансов на истинное представление проблемного пространства. Однако любое дальнейшее увеличение размера обучения после достижения таких пределов не улучшит производительность GASVM.Более того, больший обучающий набор приводит к более высоким временным затратам на обучение. (2) Аномальные шаблоны с малыми величинами сдвига требуют большего представления распределения плотности с помощью больших обучающих наборов. (3) Аномальные шаблоны с большими величинами сдвига требуют меньших наборов обучающих данных, так как их легче идентифицировать. Это связано с тем, что аномальные модели с большими величинами сдвига имеют более сильные особенности, которые легче отделяются от других аномальных моделей.