Расчёт кубатуры — Серебряный Бор
| Размер доски, мм | Количество досок при длине 6м в 1 м3 пиломатериалов | Объем одной доски длиной 6м, м 3 |
|---|---|---|
25х100 | 66,6 | 0,015 |
25х120 | 55,5 | 0,018 |
25х150 | 44,4 | 0,022 |
25х200 | 33,3 | 0,03 |
40х100 | 41,6 | 0,024 |
40х120 | 34,7 | 0,0288 |
40х150 | 27,7 | 0,036 |
40х200 | 20,8 | 0,048 |
50х50 | 66,6 | 0,015 |
50х100 | 33,3 | 0,03 |
50х120 | 27,7 | 0,036 |
50х150 | 22,2 | 0,045 |
50х200 | 16,6 | 0,06 |
50х250 | 13,3 | 0,075 |
Брус:
| Размер бруса, мм | Количество брусов при длине 6м в кубометре пиломатериалов | Объем одного бруса длиной 6м, куб. м м |
|---|---|---|
75х150 | 14,8 | |
100х100 | 16,6 | 0,06 |
100х150 | 11,1 | 0,09 |
100х200 | 8,3 | 0,12 |
150х150 | 7,4 | 0,135 |
150х200 | 5,5 | 0,18 |
150х300 | 3,7 | 0,27 |
200х200 | 4,1 | 0,24 |
Многие покупатели пиломатериалов задаются вопросом: сколько оцилиндрованных брёвен в одном кубометре. Давайте разберёмся с этим вопросом раз и навсегда, ведь посчитать кубатуру оцилиндровки так просто. С начало нужно вычислить объём одного бревна по простой формуле:
| πr² · H |
где π — это 3,14, r — радиус бревна, H — длина бревна.
Возьмем для примера оцилиндрованное бревно диаметром 200 мм, длиной 6 м и рассчитаем его объём. Т.к. мы считаем кубические метры, то все величины тоже должны быть в метрах:
3,14 · (0,1м)² · 6 = 0,1884 м³
Т.е. объём одного оцилиндрованного бревна диаметром 200 мм равен 0,1884 м³.
Дальше можно рассчитать сколькооцилиндрованных брёвен в одном кубометре древесины. Для этого же самого бревна расчёты будут такими: 1м³ / 0,1884м³ = 5,3. Т.е. в одном кубическом метре 5,3 оцилиндрованных бревна.
Для самых распространенных размеров приведена таблица расчёта кубатуры оцилиндрованных брёвен:
Диаметр бревна, мм | 180 | 200 | 220 | 240 | 260 | 280 |
Количество оцилиндрованных брёвен (шестиметровых) в 1 м³ | 6,5 | 5,3 | 4,38 | 3,69 | 3,14 | 2,7 |
м³ в оцилиндрованном бревне | 0,1526 | 0,1884 | 0,228 | 0,271 | 0,318 | 0,369 |
Погонные метры в 1 м³ | 39,3 | 32,0 | 26,3 | 22,1 | 18,9 | 16,3 |
Расчет кубатуры оцилиндрованного бревна на дом: таблица (видео)
Расчет оцилиндрованного бревна на дом предельно прост благодаря высокому качеству материала, стабильной геометрии каждого венца. Тем не менее придется учесть ряд факторов согласно рекомендациям специалистов. Это избавит от излишних отходов кроя при выборе сложной архитектуры, позволит выбрать минимально возможный запас для снижения бюджета строительства. Расчет кубатуры оцилиндрованного бревна позволит сократить расходы при покупке, так как поштучно пиломатериал стоит дороже.
Тем не менее придется учесть ряд факторов согласно рекомендациям специалистов. Это избавит от излишних отходов кроя при выборе сложной архитектуры, позволит выбрать минимально возможный запас для снижения бюджета строительства. Расчет кубатуры оцилиндрованного бревна позволит сократить расходы при покупке, так как поштучно пиломатериал стоит дороже.
Виды оцилиндрованного бревна.
Особенности оцилиндровки при вычислении необходимого объема
Расчет оцилиндровки для коттеджа, бани основывается на нескольких характеристиках материала:
- длина – эталоном является 6 м, хотя некоторые производители выпускают 4 м пиломатериал, элементы венцов нестандартной длины;
- диаметр – на этапе проектирования важно учесть наличие облицовки фасадов, климатические, эксплуатационные особенности региона.
Например, для расчета коттеджа с планируемым декорированием фасадов можно заложить в проект меньший диаметр элементов, установить под наружную облицовку слой утеплителя. При этом сохранится необходимая прочность силового каркаса, снизятся теплопотери в стенах, сроки, бюджет строительства.
При этом сохранится необходимая прочность силового каркаса, снизятся теплопотери в стенах, сроки, бюджет строительства.
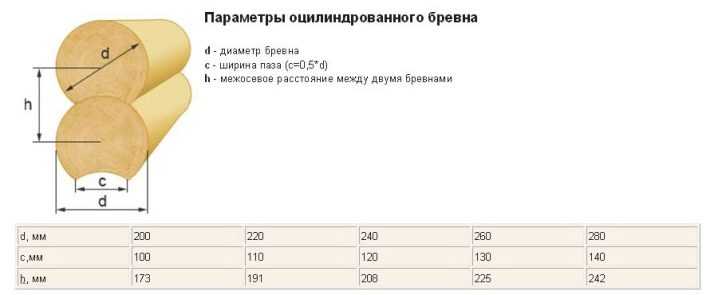
Особенностью оцилиндрованного бревна является его профилирование. Выборка продольного паза, угловых чаш осуществляется в процессе производства, что обеспечивает идеальную геометрию стен, снижение расхода межвенцового утеплителя (джут либо пакля).
Шаблонные размеры оцилиндрованного бревна.
В срубе одноэтажного коттеджа при выборе разного диаметра материала будет неодинаковое количество венцов. Чтобы вычислить их количество самостоятельно, используются стандартные соотношения рабочей высоты оцилиндровки в зависимости от ее диаметра, ширины продольного паза (см):
- 22,5 – для Ø26 с пазом 13;
- 20,8 – для Ø24 с пазом 12;
- 19,1 – для Ø22 с пазом 11;
- 17,3 – для Ø20 с пазом 10;
- 15,6 – для Ø18 с пазом 9.
Например, 3-метровый сруб из оцилиндрованного бревна Ø240 мм будет содержать в себе следующее количество венцов:
3 000/208 = 14,42, округленное до 15 штук.
С учетом выступов по углам, по чертежу жилища можно подсчитать погонаж каждого венца. Для приведенного на картинке сруба это значение составит:
9 + 6 + 9 + 6 + 6 = 42 п. м.
Умножив погонаж на количество венцов, можно получить общее количество погонных метров:
42 х 15 = 630 п. м.
Этот предварительный расчет уточняется на следующих этапах для окончательного результата сметы.
Даже при указанных габаритах здания в срубе из оцилиндрованного бревна получается небольшая полезная площадь. Стандартной длины пиломатериала хватает только на торцы, длинные стены приходится наращивать. Смещение рядности половинок целого оцилиндрованного бревна является обязательным для каждого венца. Поэтому понадобится:
Расчет кубатуры оцилиндрованного бруса.
5 целых элементов + 2 половинки (каждый венец).
Сруб из оцилиндрованного бревна должен учитывать стандартную длину пиломатериала. Достаточно разрезать целую деталь, чтобы получить необходимые 9 м каждого ряда длинной стороны.
С учетом проемов (оконные блоки по 7 венцов, дверные – по 10 рядов) для домов из сруба данного проекта вычитается необходимое количество погонных метров пиломатериала:
- окна – ((3 х 1 400) х 7) + ((1 х 1 200) х 7) = 29 400 + 8 400 = 37,8 п.м.;
- двери – (900 х 2) х 10 = 18 п. м.
Для сруба потребуется 630 – 37,8 – 18 = 574,2 п.м. оцилиндровки. Большинство производителей при пересчете кубатуры отдельного бревна округляют цену в большую сторону.
При крупных объемах это значительно увеличивает бюджет строительства, поэтому специалисты рекомендуют самостоятельным застройщикам дополнительно представить штучное количество кубами.
Вернуться к оглавлению
Расчет кубатуры материала
Подсчитать объем пиломатериала можно по стандартной формуле:
R2 х π х L, где L, R – длина и радиус пиломатериала соответственно.
Расчет кубатуры материала для дома по приведенному проекту:
0,122 х 3,14 х 574,2 = 25,96 кубов.
Расчет сруба должен учитывать 3-7% неликвидных обрезков при крое материала дома. Поэтому при полученных данных рекомендуется указать объем бревен в доме 27,3 м
PostgreSQL: Документация: 12: 9.3. Математические функции и операторы
Математические операторы предусмотрены для многих типов PostgreSQL. Для типов без стандартных математических соглашений (например, типы даты/времени) мы опишем фактическое поведение в последующих разделах.
В таблице 9.4 показаны доступные математические операторы.
Таблица 9.4. Математические операторы
| Оператор | Описание | Пример | Результат |
|---|---|---|---|
+ | дополнение | 2 + 3 | 5 |
- | вычитание | 2 - 3 | -1 |
* | умножение | 2 * 3 | 6 |
/ | деление (целочисленное деление усекает результат) | 4 / 2 | 2 |
% | по модулю (остаток) | 93,0 | 8 |
|/ | квадратный корень | |/ 25,0 | 5 |
||/ | кубический корень | ||/ 27,0 | 3 |
! | факториал () вместо ) | 5 ! | 120 |
!! | factorial в качестве оператора префикса (устарело, вместо этого используйте factorial() ) | !! 5 | 120 |
@ | абсолютное значение | при -5,0 | 5 |
и | побитовое И | 91 и 15 | 11 |
| | побитовое ИЛИ | 32 | 3 | 35 |
# | побитовое исключающее ИЛИ | 17 # 5 | 20 |
~ | побитовое НЕ | ~1 | -2 |
<< | побитовый сдвиг влево | 1 << 4 | 16 |
>> | побитовый сдвиг вправо | 8 >> 2 | 2 |
Побитовые операторы работают только с целочисленными типами данных, а также доступны для типов битовых строк , бит и , бит с переменным значением , как показано в таблице 9.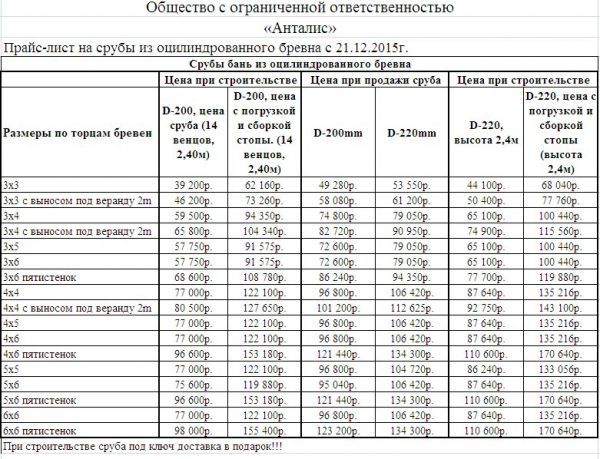
В таблице 9.5 показаны доступные математические функции. В таблице дп обозначает двойная точность . Многие из этих функций представлены в нескольких формах с разными типами аргументов. Если не указано иное, любая заданная форма функции возвращает тот же тип данных, что и ее аргумент. Функции, работающие с данными двойной точности , в основном реализованы поверх библиотеки C хост-системы; поэтому точность и поведение в граничных случаях могут различаться в зависимости от хост-системы.
Таблица 9.5. Математические функции
| Функция | Тип возврата | Описание | Пример | Результат |
|---|---|---|---|---|
| (то же, что и ввод) | абсолютное значение | абс(-17,4) | 17,4 |
| дп | кубический корень | тбт(27. | 3 |
| (то же, что и ввод) | ближайшее целое число, большее или равное аргументу | потолок(-42,8) | -42 |
| (то же, что и ввод) | ближайшее целое число, большее или равное аргументу (то же, что и ceil ) | потолок(-95,3) | -95 |
| дп | радиан в | градуса градусов(0,5) | 28. |
| ||||
| (то же, что и ввод) | экспоненциальный | эксп(1.0) | 2,71828182845905 |
| цифровой | факториал | факториал(5) | 120 |
| (то же, что и ввод) | ближайшее целое число, меньшее или равное аргументу | этаж(-42,8) | -43 |
| (то же, что и ввод) | натуральный логарифм | п(2. | 0,693147180559945 |
| (то же, что и ввод) | по основанию 10 логарифм | журнал(100.0) | 2 |
| (то же, что и ввод) | по основанию 10 логарифм | лог10(100.0) | 2 |
| цифровой | логарифм по основанию b | журнал(2. | 6.0000000000 |
| (то же, что и типы аргументов) | остаток от у / x | мод(9,4) | 1 |
| дп | Константа «π» | пи() | 3.14159265358979 |
| дп | a в степени b | мощность(9. | 729 |
| цифровой | a в степени b | мощность(9.0, 3.0) | 729 |
| дп | градус в радиан | радиан(45.0) | 0,785398163397448 |
| (то же, что и ввод) | округлить до ближайшего целого числа | круглый(42. | 42 |
| цифровой | округлить до с десятичных разрядов | круглый(42.4382, 2) | 42,44 |
| целое число | шкала аргумента (количество знаков после запятой в дробной части) | шкала(8.41) | 2 |
| (то же, что и ввод) | знак аргумента (-1, 0, +1) | знак(-8. | -1 |
| (то же, что и ввод) | квадратный корень | кв.(2.0) | 1.4142135623731 |
| (то же, что и ввод) | обрезать до нуля | ствол(42,8) | 42 |
| цифровой | усечь до с десятичных разрядов | ствол(42. | 42,43 |
3 | Интервал | возвращает номер сегмента, которому операнд будет присвоен в гистограмме, имеющей счетчиков сегментов одинаковой ширины, охватывающих диапазон от b1 до 7 b3 7 ; возвращает 0 или для ввода вне диапазона | width_bucket(5,35, 0,024, 10,06, 5) | 3 |
| Интервал | возвращает номер сегмента, которому операнд будет присвоен в гистограмме, имеющей счетчиков сегментов одинаковой ширины, охватывающих диапазон от b1 до 7 b3 7 ; возвращает 0 или для ввода вне диапазона | width_bucket(5,35, 0,024, 10,06, 5) | 3 |
3 | Интервал | возвращает номер корзины, которому будет присвоен операнд , учитывая массив, в котором перечислены нижние границы корзин; возвращает 0 для ввода меньше первой нижней границы; пороги массив должен быть отсортирован , сначала наименьший, иначе будут получены неожиданные результаты | width_bucket(сейчас(), массив['вчера', 'сегодня', 'завтра']::timestamptz[]) | 2 |
 0)
0)  6478897565412
6478897565412 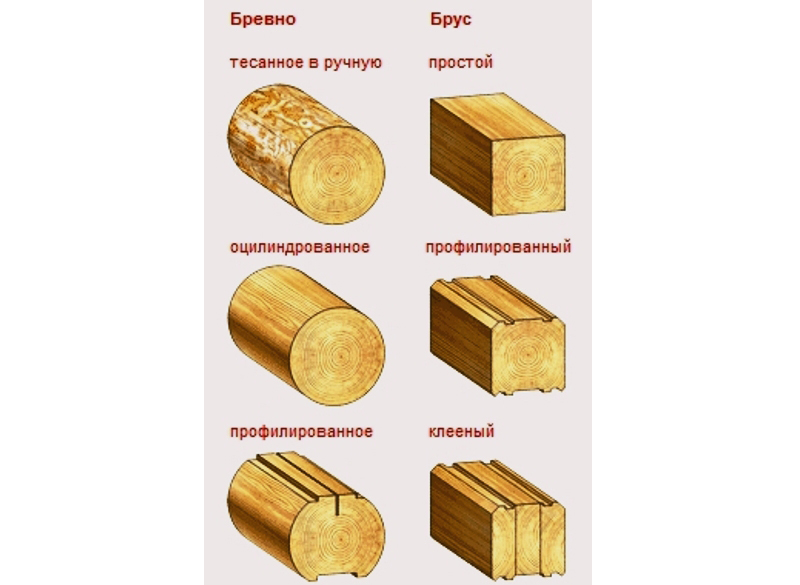 0)
0)  0, 64.0)
0, 64.0) 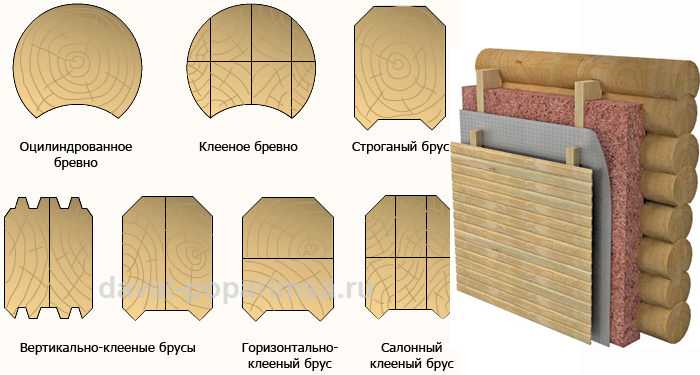 0, 3.0)
0, 3.0) 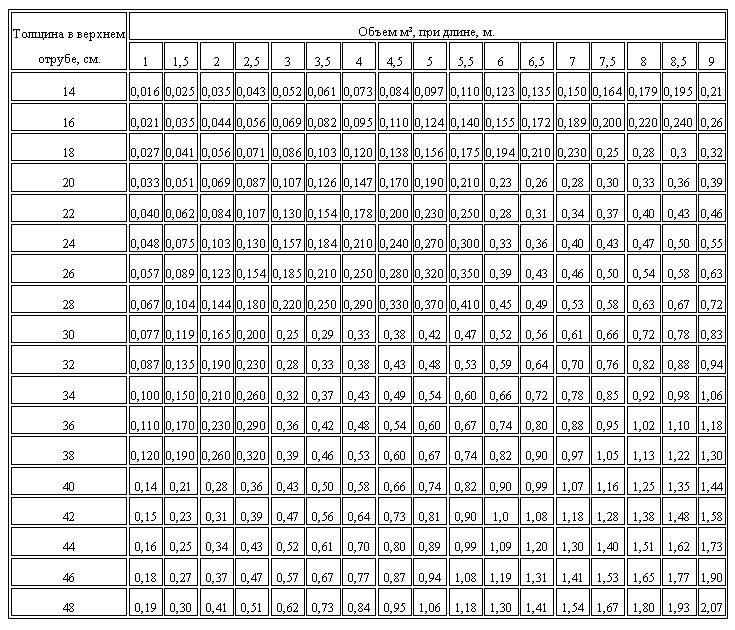 4)
4)  4)
4)  4382, 2)
4382, 2) В таблице 9. 6 показаны функции для генерации случайных чисел.
6 показаны функции для генерации случайных чисел.
Таблица 9.6. Случайные функции
| Функция | Тип возврата | Описание |
|---|---|---|
| дп | случайное значение в диапазоне 0,0 <= x < 1,0 |
| пустота | установить начальное значение для последующего random() вызовов (значение от -1,0 до 1,0 включительно) |
Функция random() использует простой линейный конгруэнтный алгоритм. Это быстро, но не подходит для криптографических приложений; см. модуль pgcrypto для более безопасной альтернативы. Если вызывается
Если вызывается setseed() , результаты последующих вызовов random() в текущем сеансе повторяются путем повторного вызова setseed() с тем же аргументом. Без каких-либо предварительных setseed() в том же сеансе, первый вызов random() получает начальное число из зависящего от платформы источника случайных битов.
В таблице 9.7 показаны доступные тригонометрические функции. Все эти функции принимают аргументы и возвращают значения типа с двойной точностью . Каждая из тригонометрических функций существует в двух вариантах: один измеряет углы в радианах, а другой измеряет углы в градусах.
Таблица 9.7. Тригонометрические функции
| Функция (радианы) | Функция (градусы) | Описание |
|---|---|---|
| | арккосинус |
| | обратная синусоида |
| | арктангенс |
| | арктангенс |
| | косинус |
| | котангенс |
| | синус |
| | тангенс |
Примечание
Другим способом работы с углами, измеряемыми в градусах, является использование показанных ранее функций преобразования единиц и радианов() . градусов()  Однако предпочтительнее использовать тригонометрические функции на основе степеней, так как это позволяет избежать ошибки округления для особых случаев, таких как 9.0032 синд(30) .
Однако предпочтительнее использовать тригонометрические функции на основе степеней, так как это позволяет избежать ошибки округления для особых случаев, таких как 9.0032 синд(30) .
В таблице 9.8 показаны доступные гиперболические функции. Все эти функции принимают аргументы и возвращают значения типа с двойной точностью .
Таблица 9.8. Гиперболические функции
| Функция | Описание | Пример | Результат |
|---|---|---|---|
| гиперболический синус | синх(0) | 0 |
| гиперболический косинус | кош(0) | 1 |
| гиперболический тангенс | танх(0) | 0 |
| обратный гиперболический синус | асинх(0) | 0 |
| Арктический гиперболический косинус | акош(1) | 0 |
| аркгиперболический тангенс | атанх(0) | 0 |
Как эффективно извлекать данные из куба OLAP, полагаясь на T-SQL
Введение
В прошлом месяце я провел две предварительные конференции по бизнес-аналитике в Южной Африке. Интересный запрос возник в ходе предварительной конференции в Кейптауне. Потребовался подход к извлечению данных из куба OLAP, который позволил бы избежать интенсивного использования многомерных выражений и больше полагаться на T-SQL. Его главная забота заключалась в фильтрации данных во время выполнения через внешний интерфейс отчета.
Интересный запрос возник в ходе предварительной конференции в Кейптауне. Потребовался подход к извлечению данных из куба OLAP, который позволил бы избежать интенсивного использования многомерных выражений и больше полагаться на T-SQL. Его главная забота заключалась в фильтрации данных во время выполнения через внешний интерфейс отчета.
В этом «горячем чате» мы сделаем именно это, используя куб, который поставляется с новой базой данных Microsoft «WideWorldImporters», и мы узнаем, как мы можем получить от этого
1 2 3 4 5 6 7 8 9 |
ВЫБЕРИТЕ НЕПУСТОЙ { [Меры].[Количество - Продажа], [Меры].[Цена за единицу - Продажа], [Меры].[Доход], [Меры].[Идентификатор счета-фактуры Первой мировой войны] } ON COLUMNS , НЕПУСТОЙ { ([Клиент].[Клиент].[Клиент].ALLMEMBERS * [Город].[Город].[Город].ALLMEMBERS * [Дата счета-фактуры]. * [Город].[Штат, провинция].[Штат, провинция].ALLMEMBERS } } СВОЙСТВА ИЗМЕРЕНИЯ MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM [Wide World Importers DW] СВОЙСТВА КЛЕТКИ ЗНАЧЕНИЕ, BACK_COLOR, FORE_COLOR, FORMATING, FORMATING FONT_NAME, FONT_SIZE, FONT_FLAGS
|
 [Дата].[Дата ].ALLMEMBERS
[Дата].[Дата ].ALLMEMBERSк этому!
Подготовительные работы
Если у вас нет копии WideWorldImportersDW, загрузите копию реляционной базы данных. Реляционную базу данных можно найти по этой ссылке
Просто восстановите базу данных в нужный экземпляр SQL Server 2016.
Теперь мы готовы начать.
Начало работы
Открыв Visual Studio 2015 или последнюю версию SQL Server Data Tools для SQL Server 2016, мы создаем новый проект служб Analysis Services, как показано ниже.
Открыв Visual Studio of SQL Server Data Tools, мы выбираем «Создать» и «Проект» (см.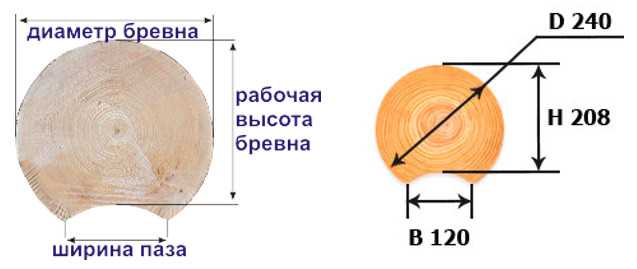 выше).
выше).
Мы даем нашему проекту имя и выбираем опцию «Многомерные сервисы и интеллектуальный анализ данных…» (как показано выше). Нажимаем «ОК».
В поле зрения появляется наша проектная поверхность (см. выше).
Наша первая задача — добавить источник данных. Щелкните правой кнопкой мыши папку «Источники данных», показанную выше.
Выбираем «Новый источник данных» (см. скриншот выше).
Появится «Мастер источников данных». Нажимаем «Далее» (см. выше).
Нам представлен список существующих подключений к данным. Читатель с «орлиным взглядом» отмечает, что соединение с реляционной базой данных уже существует, однако мы создадим НОВОЕ соединение для тех из нас, кто не знаком с созданием НОВЫХ соединений.
Мы нажимаем кнопку «Создать», как показано выше.
Появится мастер «Диспетчер подключений». Мы устанавливаем имя экземпляра нашего сервера и выбираем реляционную базу данных «WideWorldImportersDW» (как видно выше). Затем мы проверяем соединение и нажимаем «ОК», чтобы выйти из мастера.
Затем мы проверяем соединение и нажимаем «ОК», чтобы выйти из мастера.
Мы снова оказываемся в «Мастере источников данных». Мы выбираем наше новое соединение и нажимаем «Далее», чтобы продолжить.
Читатель заметит, что теперь нас просят ввести нашу «Информацию о олицетворении». В этом случае я решил использовать конкретное имя пользователя и пароль. Эти данные будут использоваться для проверки того, что у нас есть необходимые права для публикации нашего проекта на сервере анализа.
Наконец, мы даем нашему источнику данных имя и нажимаем «Готово», чтобы завершить процесс (см. Выше).
Источник данных, который мы только что создали, теперь можно увидеть в папке «Источники данных», как показано выше.
Создание «представления источника данных»
Наша следующая задача — создать «представление источника данных». Хотя мы создали подключение к данным, все, что делает это подключение, — это разрешает нашему проекту доступ к реляционной базе данных.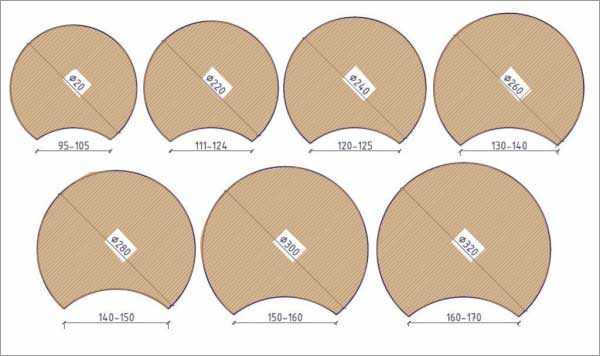 Теперь мы должны указать нашему проекту, какие данные мы хотим просмотреть, и это достигается с помощью «Просмотра источника данных».
Теперь мы должны указать нашему проекту, какие данные мы хотим просмотреть, и это достигается с помощью «Просмотра источника данных».
Щелкните правой кнопкой мыши папку «Представления источников данных» и выберите «Новое представление источника данных» (как видно выше).
Появится «Мастер представления источника данных». Нажимаем «Далее».
Теперь мастер показывает нам наше подключение к данным «Wide World Importers DW», которое мы создали выше. Выбираем это подключение и нажимаем «Далее».
Появится список таблиц. Мы выбираем таблицы, с которыми хотим работать, как показано ниже:
Просматривая диалоговое окно «Включенные объекты», мы отмечаем таблицы, которые мы должны включить в наше представление. Все «взаимосвязи» таблиц (например, ключи и внешние ключи) будут соблюдаться, и поэтому мы должны убедиться, что все необходимые таблицы включены в создаваемую нами модель.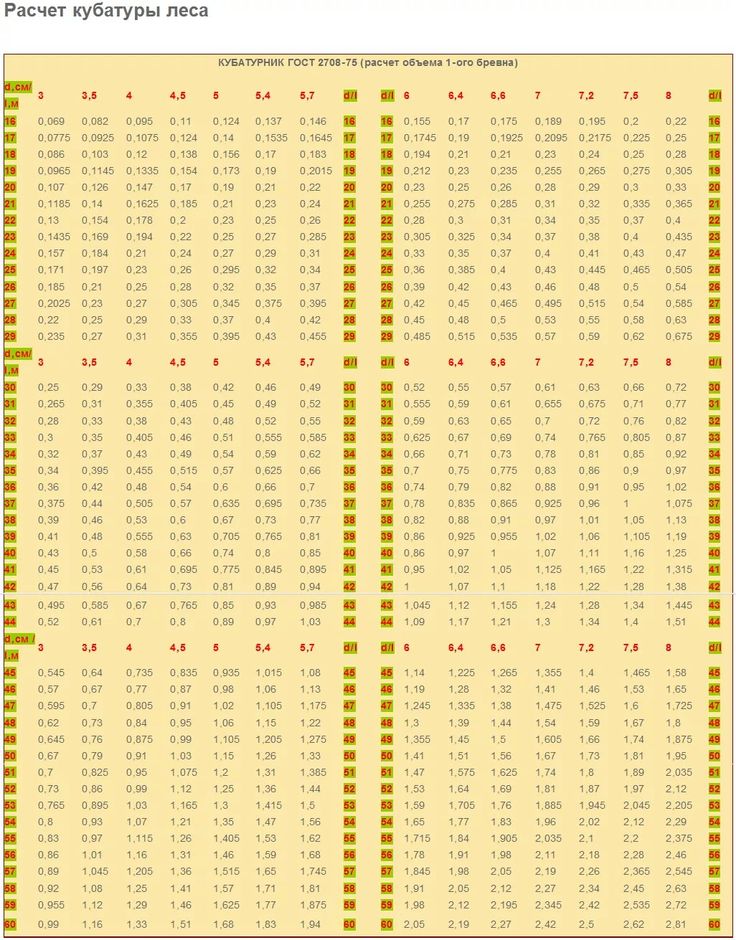 Невыполнение этого требования приведет к проблемам внутри куба.
Невыполнение этого требования приведет к проблемам внутри куба.
По завершении «представления источника данных» мы возвращаемся к нашей поверхности рисования, и появляется наша завершенная «диаграмма отношений» (см. выше).
Создание нашего куба
Чтобы создать нужный нам куб, мы щелкаем правой кнопкой мыши папку «Кубики» и выбираем «Новый куб» (см. ниже).
Появится «Мастер кубов».
Нажимаем «Далее» (см. выше).
Мы выбираем «Использовать существующие таблицы» (см. выше). Теперь мы нажимаем «Далее».
Нас просят выбрать наши таблицы «Факты/Показатели». Это таблицы, содержащие такие данные, как денежная стоимость покупок/продаж/заказов. Эти таблицы представляют собой измеримых таблиц.
Выбираем Заказ, Покупка и Продажа (см. выше). Затем мы нажимаем «Далее».
Теперь нам представлены «атрибуты» (этих таблиц фактов), которые будут включены в куб. У нас есть возможность удалить любые нежелательные атрибуты, однако для нашего настоящего упражнения мы примем все атрибуты. Нажимаем «Далее».
У нас есть возможность удалить любые нежелательные атрибуты, однако для нашего настоящего упражнения мы примем все атрибуты. Нажимаем «Далее».
Выбор наших измерений или «качественных признаков»
Теперь нас просят выбрать наши «Размеры» (см. выше). Выбираем «Дата», «Товар на складе», «Клиент» и «Город» (см. выше). Нажимаем «Далее».
Нам показаны поля в Измерениях, и мы нажимаем «Готово».
Настройка размеров
Прежде чем продолжить, у нас есть еще одна задача, которую нужно выполнить в наших измерениях. Хотя сами измерения существуют, не все необходимые АТРИБУТЫ присутствуют в самом «измерении» (см. ниже).
Двойной щелчок по измерению «Клиент» (см. выше) открывает редактор атрибутов. Отметим, что показан только ключ. Нам требуются дополнительные атрибуты, и эти атрибуты расположены в таблице Customer, показанной выше.
Мы перетаскиваем «Счет на имя», «Категорию», «Клиент» и «Почтовый индекс» в поле «Атрибуты» из нижнего правого списка атрибутов «Клиент» (см. выше).
выше).
Мы делаем то же самое для атрибутов «Город», как показано выше.
Теперь мы можем обработать наш куб и извлечь информацию из куба.
Обработка нашего куба
Перейдя на вкладку «Проект», выбираем «Свойства» (см. выше).
Теперь мы должны указать системе, где мы хотим развернуть наш проект, а также дать имя целевой базе данных OLAP (см. выше). Мы нажимаем «ОК», чтобы покинуть «Страницу свойств».
Теперь мы «построим» или попытаемся «скомпилировать» наше решение, чтобы обнаружить любые ошибки.
«Сборка» удалась.
Еще раз щелкните правой кнопкой мыши имя нашего проекта (см. выше) и выберите «Процесс» в контекстном меню (см. выше).
Нам сообщают, что «Контент сервера устарел». Мы сообщаем системе, что хотим собрать и развернуть проект.
Нам сообщают, что развертывание прошло успешно (см. выше зеленым цветом). Появится диалоговое окно «Обработка базы данных» с вопросом, хотим ли мы обработать базу данных. Нажимаем «Выполнить».
выше зеленым цветом). Появится диалоговое окно «Обработка базы данных» с вопросом, хотим ли мы обработать базу данных. Нажимаем «Выполнить».
По завершении обработки и при отсутствии ошибок нам сообщается «Успешная обработка» (см. выше). Эта «обработка» позволила создать агрегированные финансовые результаты для всех клиентов, для всех городов в области заданных данных. Закрываем все открытые окна обработки.
Теперь мы снова оказываемся внутри дизайнерской поверхности Cube. Посмотрим, какие результаты мы можем наблюдать.
Нажав на вкладку «Браузер», вы откроете «Браузер куба» (см. выше).
Перед созданием нашего первого запроса MDX мы решаем, что хотим создать вычисляемое поле для «Дохода».
Доход определяется как проданное количество * цена за единицу. Мы нажимаем на вкладку «Расчеты» и создаем новый «Расчет».
Наше новое вычисляемое поле можно увидеть выше, и оно определяется как «Количество — Продажа» * «Цена за единицу — Продажа».
Теперь, когда наше вычисляемое поле разработано, мы можем просмотреть наш куб. Мы повторно обрабатываем куб, а затем нажимаем на вкладку «Браузер» (см. выше).
Мы отмечаем, что наше вычисляемое поле появляется под таблицами мер. Это нормально, и расчет готов к использованию.
Мы перетаскиваем «Количество-Продажа», «Цена за единицу — Продажа» и наше рассчитанное поле «Доход» на поверхность дизайна. Читатель заметит, что агрегированные значения всех данных показаны в одной строке выше. Далее с помощью калькулятора и перемножив цифру между собой, убеждаемся, что наше вычисляемое поле работает точно. Единственная проблема заключается в том, что одна агрегированная строка мало полезна.
Добавляя «Имя клиента», «Город», «Дату выставления счета», «Номер счета» и «Область штата», мы видим доход от каждого счета на каждую дату счета. Короче говоря, у нас есть более значимые результаты.
Нажав на вкладку «Режим дизайна», мы видим, что код MDX стоит за извлечением данных, которое мы создали выше. Этот код становится важным, так как мы будем использовать этот код для запроса отчета, который мы создадим через несколько минут.
Этот код становится важным, так как мы будем использовать этот код для запроса отчета, который мы создадим через несколько минут.
В качестве двойной проверки того, что мы на самом деле находимся на правильном пути, мы теперь вызываем SQL Server Management Studio и регистрируемся на нашем сервере OLAP. Мы выбираем только что созданную базу данных SQLShack OLAP.
Используя код MDX из нашего проекта Visual Studio, мы можем скопировать и вставить тот же код в браузер куба в SQL Server Management Studio. Результаты можно увидеть выше.
«Дикая карта»
Прежде чем приступить к созданию наших отчетов, нам нужно выполнить одну последнюю задачу. Мы собираемся создать связанный сервер с нашей базой данных Analysis, которую мы только что построили.
Это код, который мы будем использовать, а сам код можно найти в Приложениях 2.
Теперь, когда наш связанный сервер создан, мы можем начать с нашего запроса отчета!
Создание запроса отчета
Открыв SQL Server Management Studio, мы открываем новый запрос.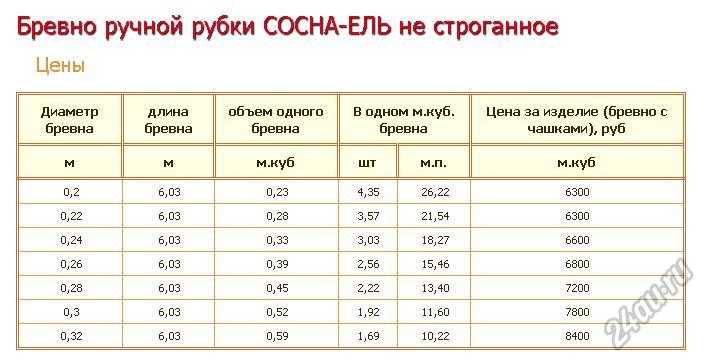 Используя полученный код DMX, мы помещаем этот код в «OpenQuery», используя наш новый связанный сервер (см. ниже).
Используя полученный код DMX, мы помещаем этот код в «OpenQuery», используя наш новый связанный сервер (см. ниже).
Теперь «мудрый акр» спросит, зачем мы это делаем. Ответ довольно прост. Подзапрос — это запрос MDX, а внешний запрос разработан на T-SQL! Разработанный в T-SQL позволяет нам фильтровать набор результатов, используя все «вкусности», такие как логика прецедентов в предикате части T-SQL. Да, мы извлекаем из куба все ОБЪЕДИНЕННЫЕ данные, однако если данные правильно агрегированы во время обработки куба, то «попадание» не так уж и плохо.
Единственный момент, который не сразу бросается в глаза, заключается в том, что истинные имена извлеченных полей не такие, как можно было бы ожидать. Обычно и разово мы публикуем результаты запроса в таблицу. Это позволит нам определить правильные имена полей с точки зрения SQL Server (см. ниже).
Немного изменив запрос, теперь мы можем добавить предикат даты T-SQL (см. ниже):
Читатель заметит, что даты начала и окончания жестко привязаны. Мы собираемся изменить это, чтобы предикат принимал дату начала и окончания из параметров (см. ниже):
Мы собираемся изменить это, чтобы предикат принимал дату начала и окончания из параметров (см. ниже):
Наша последняя модификация нашего запроса заключается в создании хранимой процедуры, которая будет использоваться нашим отчетом.
Читатель заметит, что мы выбрали подмножество полей, необходимых для нашего отчета. Напоминаем, что имена полей кажутся немного неуклюжими, однако именно так их «видит» SQL Server.
Создание нашего отчета
Еще раз открываем Visual Studio 2015 или SQL Server Data Tools версии 2010 или выше. Однако на этот раз мы выбираем «Проект служб отчетов» (см. выше). Даем нашему проекту имя и нажимаем «ОК» (см. выше).
Создав проект, мы попали в нашу область дизайна. Наша следующая задача — создать новый «Общий источник данных», который будет подключаться к нашей таблице реляционной базы данных . Как мы обсуждали на прошлых встречах, базу данных можно сравнить с водопроводным краном на стене вашего дома. Тогда «источник данных» можно уподобить водяному шлангу, по которому данные будут доставляться туда, где они требуются.
Тогда «источник данных» можно уподобить водяному шлангу, по которому данные будут доставляться туда, где они требуются.
Щелкните правой кнопкой мыши папку «Общие источники данных» (как указано выше). Выбираем «Добавить новый источник данных».
Откроется диалоговое окно «Свойства подключения». Мы сообщаем системе имя экземпляра SQL Server и базы данных, к которой мы хотим подключиться (см. выше).
Мы возвращаемся в диалоговое окно «Свойства источника общих данных» (как видно выше). Нажимаем «ОК», чтобы продолжить.
Настройка нашего нового отчета
Нашей следующей задачей является создание нашего отчета. Для этого щелкните правой кнопкой мыши папку «Отчеты» и выберите «Добавить», а затем «Новый элемент».
Мы попадаем на экран «Добавить новый элемент». Мы выбираем «Отчет» и даем нашему отчету имя (как показано выше). Нажимаем «Добавить», чтобы продолжить.
Мы оказываемся на нашей поверхности дизайна отчета.
Теперь, когда мы находимся в области дизайна отчета, наша первая задача — определить два параметра, которые можно использовать для передачи даты начала и окончания в наш запрос отчета. Напоминаем читателю, что когда мы создавали исходный запрос, мы извлекали записи за определенный период времени. Этот временной интервал будет определяться аргументами, переданными в запрос через два параметра.
Щелкаем правой кнопкой мыши по папке «Параметры» и выбираем «Добавить параметр» (см. выше).
Присваиваем имя нашему параметру и устанавливаем тип данных «Дата/Время» (см. выше).
Аналогичным образом мы создаем и инициализируем наш параметр End Date.
Наш рисунок «холст» теперь выглядит следующим образом (см. выше).
Создание нашего локального набора данных
Теперь, когда мы создали наши параметры, нам нужно выполнить последнюю структурную задачу — создать набор данных.
Чтобы создать этот набор данных (который можно сравнить с лейкой, которая содержит «подмножество» воды из крана в доме), мы щелкаем правой кнопкой мыши папку «Набор данных» и выбираем «Добавить набор данных». Как и в случае с канистрой для воды, наш набор данных будет содержать данные, извлеченные из нашей базы данных OLAP с помощью нашего запроса И нашего связанного сервера.
Откроется диалоговое окно «Свойства набора данных». Мы даем нашему набору данных имя, и, поскольку наш набор данных является «локальным» набором данных, нам необходимо создать новый локальный источник данных, который будет подключен к «Общему источнику данных», который мы только что создали. Нажимаем кнопку «Новый» (см. выше).
Нажав кнопку «Создать», мы попадаем на экран диалога «Свойства источников данных». Мы даем нашему локальному источнику данных имя и связываем его с нашим «Общим источником данных» (см. выше). Нажимаем «ОК», чтобы продолжить.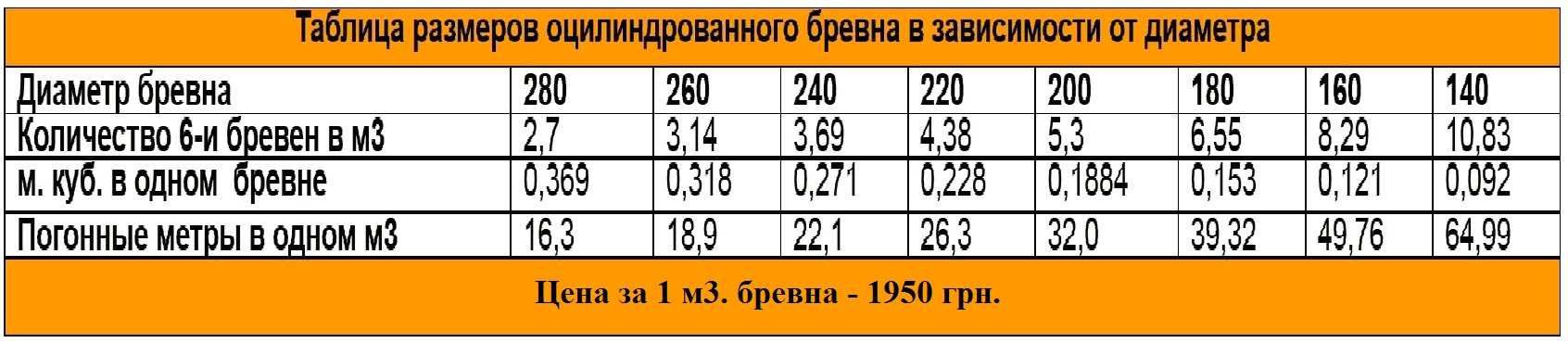 Мы возвращаемся к экрану «Свойства набора данных» (см. ниже).
Мы возвращаемся к экрану «Свойства набора данных» (см. ниже).
Мы выбираем «Хранимая процедура» для «Тип запроса» и с помощью раскрывающегося списка выбираем хранимую процедуру, которую мы создали выше (см. выше).
Выбрав нашу хранимую процедуру, мы нажимаем кнопку «Обновить поля», чтобы вывести список полей, которые будут доступны для нашего отчета (см. выше).
Нажав на вкладку «Поля» (в верхнем левом углу снимка экрана выше), мы теперь можем увидеть поля, которые станут доступными для нашего отчета.
Нажав на вкладку «Параметры», мы отмечаем, что два параметра, которые мы , созданные с помощью нашей хранимой процедуры , теперь видны. Это «Имя параметра». «Значение параметра» будет получено из пользовательского ввода (в качестве аргументов) через два параметра отчета, которые мы только что создали. Следовательно, мы должны назначить правильные аргументы параметрам хранимой процедуры.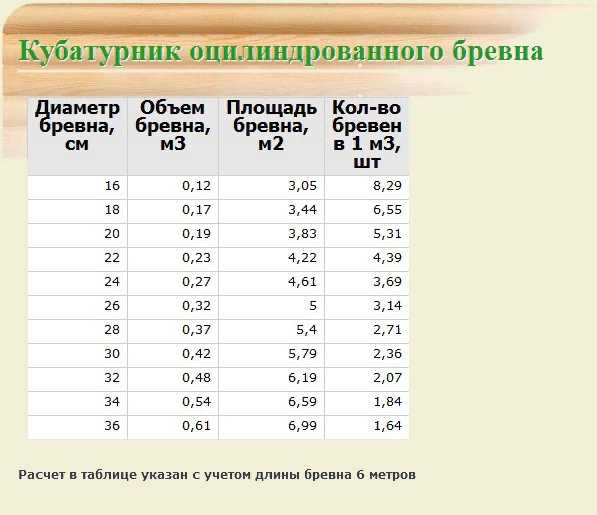
На скриншоте выше показана правильная конфигурация.
Добавление элементов управления отчетом
Теперь, когда у нас есть инфраструктура отчетов или «сантехника», мы можем добавить необходимые элементы управления, необходимые для того, чтобы конечный пользователь мог просматривать свои данные.
`
Наша поверхность дизайна показана выше, проницательный читатель заметит два элемента управления календаря (параметры), которые мы только что создали.
Мы перетаскиваем элемент управления «Матрица» из панели инструментов на поверхность рисования (см. выше).
Мы нажимаем F4, чтобы открыть окно свойств матрицы, которую мы только что добавили на нашу рабочую поверхность. Мы устанавливаем его свойство «DataSetName» на имя набора данных, который мы создали выше (см. выше).
Поскольку мы не будем использовать «Группировку столбцов», мы решили удалить группу столбцов, щелкнув правой кнопкой мыши «Группу столбцов» и выбрав «Удалить группу» (см.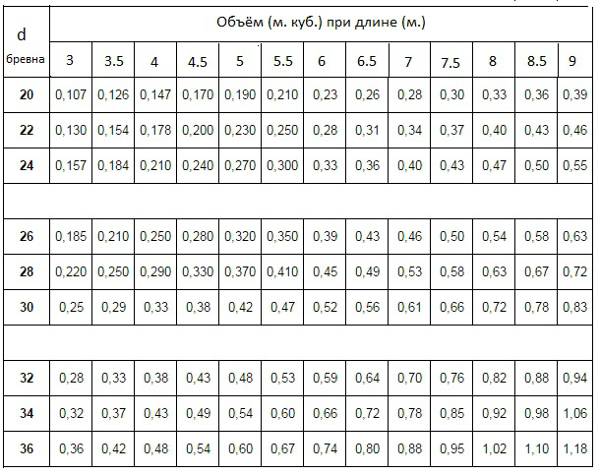 выше).
выше).
Нас спрашивают, хотим ли мы удалить группу и связанные с ней строки и столбцы ИЛИ просто удалить саму группу. Выбираем «Удалить только группу» (см. выше).
Однако мы хотим установить «Группировку строк», поскольку мы хотим просматривать наши данные как суммирование выручки по номеру счета-фактуры. Нажимаем на вкладку «Свойства группы».
На снимке экрана выше мы установили группировку на основе номера счета.
Наша следующая задача — добавить поля из хранимой процедуры в нашу матрицу. Это показано выше. Мы подробно обсуждали этот процесс в многочисленных прошлых «чатах».
На этом построение нашего отчета завершено.
Давайте попробуем
Перейдя на вкладку «Предварительный просмотр», мы выбираем элемент управления «Календарь» и устанавливаем дату начала на 01.01.2013 (см. выше).
Аналогичным образом мы устанавливаем дату окончания на 05.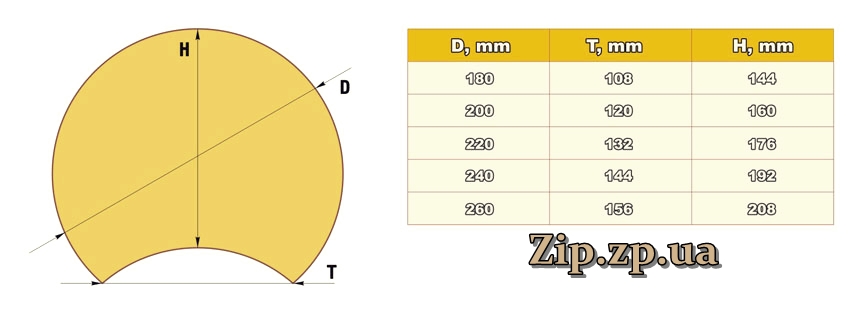 01.2013 (см. выше). Теперь нажимаем «Просмотреть отчет».
01.2013 (см. выше). Теперь нажимаем «Просмотреть отчет».
Мы отмечаем, что наши данные теперь видны пользователю и что наш отчет завершен. Естественно, читатель захочет отсортировать и отформатировать данные. Мы также обсуждали это на многочисленных прошлых встречах, однако приведенный ниже дамп экрана показывает наши данные, отсортированные по номеру счета, а числовые значения округлены до ближайшего доллара (см. ниже).
Чтобы отшлифовать данные, необходимо преобразовать несколько полей в числовые значения. Этого проще всего добиться внутри самой хранимой процедуры. Я включил окончательный пример кода в дополнения 3 (ниже).
Выводы
Часто мы все сталкиваемся с проблемой работы с MDX. Фильтрация данных с помощью MDX является сложной задачей даже в лучшие времена. Это особенно верно, когда предикаты сложные и периодически изменяются.
Благодаря использованию небольшого фрагмента кода MDX в подзапросе мы можем извлекать необходимые данные и эффективно фильтровать их с помощью T-SQL; если мы используем связанный сервер и функцию OpenQuery.
Итак, мы подошли к концу еще одного «побочного чата». Как всегда, если есть какие-либо вопросы, пожалуйста, не стесняйтесь обращаться ко мне.
А пока «Счастливого программирования».
Добавление 1 (запрос OLAP)
ВЫБЕРИТЕ НЕПУСТОЙ { [Меры].[Идентификатор счета-фактуры за Первую мировую войну], [Меры].[Количество - Продажа], [Меры].[Цена за единицу - Продажа], [Меры].[Доход] } В КОЛОНЦАХ , НЕПУСТОЙ { ([Дата].[Дата].[Дата].ALLMEMBERS * [Город].[Город].[Город].ALLMEMBERS * [Заказчик].[Заказчик].[Заказчик].ALLMEMBERS ) } СВОЙСТВА ИЗМЕРЕНИЙ MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM [Wide World Importers DW] СВОЙСТВА ЯЧЕЙКИ VALUE, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
|
Дополнение 2 (Создание связанного сервера)
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000 214 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 |
-- Настройка связанного сервера GO EXEC sp_addlinkedserver @server='WWI2', -- локальное имя SQL, присвоенное связанному серверу
@srvproduct='', -- не используется - Поставщик OLE DB
@datasrc='STR-SIMON\Steve2016b', -- имя сервера анализа (имя компьютера)
@catalog='SQLShackOLAPMadeEasy' -- каталог/база данных по умолчанию
-- Удаление сервера -- Очистка --USE [master] --GO --GO master. --GO
|
 dbo.sp_dropserver @server = WWI2
dbo.sp_dropserver @server = WWI2 [Клиент]].[MEMBER_CAPTION]]] как Клиент ,
[Клиент]].[MEMBER_CAPTION]]] как Клиент ,